任务描述
- 假设要抽取两类实体、人名加机构名,采用BIO标签,则标签有5个分别为 \(B-Person (人名的开始部分)\\ I- Person (人名的中间部分)\\ B-Organization (组织机构的开始部分)\\ I-Organization (组织机构的中间部分)\\ O (非实体信息)\)
- 输入一句话,需要对其中每个词打标签,判断那个词是人名,那个词是机构名
BiLSTM+softmax
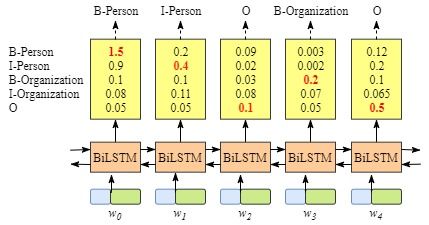
- bilstm进行特征的抽取,然后接softmax对每一个词都去取概率最大的一个标签。
- 这样会导致,B后面也会跟B或者跟O,因为softmax只会取当前预测的最大值,不会考虑前后的标签约束。
BiLSTM+CRF
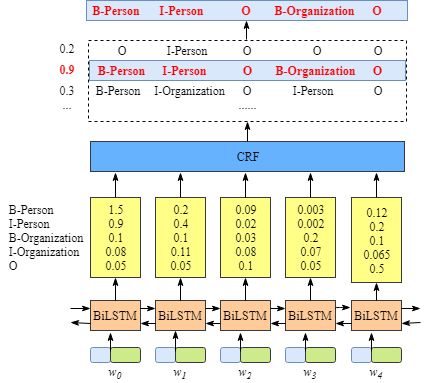
- 基于bilstm进行特征抽取,抽取特征作为crf的输入,学习句子约束进行全局的归一化。
crf
crf层学习句子的约束条件、约束条件为自动学习
状态分数
- 状态分数(发射分数),是bilstm的输出。
- 假设编号\(B-person-0, i_person-1, B-organization-2, i-organization-3, o-4\)
- \(x_{iy_j}\)表示状态分数,i表示单词的索引,\(y_j\)表示类别的索引,则\(X_{i=1,y_j=2}=x_{w_1, B_{organization}}=0.1\)表示单词\(w_1\)被预测为$B_{organization}$的分数为0.1
转移分数
- \(t_{y_i,y_j}\)表示转移分数
- \(t_{B_{person},i_{person}}=0.9\)表示从类别\(B_{person}\)转到\(i_{person}\)的分数是0.9
- 为了完善转移矩阵添加开始结束标签START,END。
- 转移矩阵中就可以看出来有用的约束,比如单词以B开头或者O开始,不会以I开头等
- 随机初始化转移矩阵,在训练过程总自己学习。
CRF损失函数
- 由两部分组成,真实路径和所有路径的总分数,理论上真实路径的分数应该是所有路径中分数最高的那个。
- 假设编号\(B-person-0, i_person-1, B-organization-2, i-organization-3, o-4,START-5.END-6\)
- 公式为:\(Loss = \frac{RealPath}{p_1+p_2,...+p_n}\)
真实路径分数
- 公式\(RealPath = 转移分数+状态分数\)
- 状态分数来自bilstm,转移分数来自crf
所有路径的总分
- 转换loss函数为:\(logLoss = log \frac{RealPath}{p_1 + p_2,...,p_n}\)
- 最小化损失函数,所以转换负号 \(logLoss = - log \frac{RealPath}{p_1 + p_2,...,p_n} = \\ = - log \frac{e^{S_{RealPath}}}{e^{S_1}+e^{S_2},..,+e^{S_n}} \\ = - (log(e^{S_{RealPath}}) - log(e^{S_1}+e^{S_2},..,+e^{S_n})) \\ = - (S_{RealPath} - log(e^{S_1}+e^{S_2},..,+e^{S_n})) \\ = - (\sum_{i=1}^N x_{i,y_i} + \sum_{i=1}^{N-1}t_{y_i,y_{i+1}} - log(e^{S_1}+e^{S_2},..,+e^{S_n}))\)
-
现在只需要计算\(log(e^{S_1}+e^{S_2},..,+e^{S_n})\)即可
- 先计算$w_0$,再计算$w_1,w_2$。Previous存储了之前步骤的结果,obs代表当前单词所带的信息 \(w_0:\\ obs = [x_{01}, x_{02}] \\ previous = None \\ TotalScore(w_0) = log(e^{x_{01}} + e^{x_{02}})\\ w_0 -> w_1 \\ obs = [x_{11}, x_{12}] \\ previous = [x_{01}, x_{02}]\\ expand previous = \left(\begin{array}{ll} x_{01} & x_{01} \\ x_{02} & x_{02} \end{array}\right)\\ expand obs = \left(\begin{array}{ll} x_{11} & x_{12} \\ x_{11} & x_{12} \end{array}\right)\\ scores = \left(\begin{array}{ll} x_{01} & x_{01} \\ x_{02} & x_{02} \end{array}\right)+\left(\begin{array}{ll} x_{11} & x_{12} \\ x_{11} & x_{12} \end{array}\right)+\left(\begin{array}{ll} t_{11} & t_{12} \\ t_{21} & t_{22} \end{array}\right) \\ \left(\begin{array}{ll} x_{01} & x_{01} \\ x_{02} & x_{02} \end{array}\right)+\left(\begin{array}{ll} x_{11} & x_{12} \\ x_{11} & x_{12} \end{array}\right)+\left(\begin{array}{ll} t_{11} & t_{12} \\ t_{21} & t_{22} \end{array}\right)\\ previous = \left[\log \left(e^{x_{00}+x_{11}+t_{11}}+e^{x_{02}+x_{11}+t_{21}}\right), \log \left(e^{x_{01}+x_{12}+t_{22}}+e^{x_{02}+x_{12}+t_{22}}\right)\right]\)
- 总结$w_0 -> w_1$ \(\begin{array}{l} \text {TotalScore}\left(w_{0} \rightarrow w_{1}\right) \\ =\log \left(e^{\text {previous}[0]}+e^{\text {previous}[1]}\right) \\ =\log \left(e^{\log \left(e^{x_{01}+z_{11}+t_{11}}+e^{x_{02}+x_{11}+t_{21}}\right)}+e^{\log \left(e^{z_{01}+x_{12}+t_{12}+e^{x_{02}+x_{12}+t_{22}}}\right)}\right) \\ =\log \left(e^{x_{01}+x_{11}+t_{11}}+e^{x_{02}+x_{11}+t_{21}}+e^{x_{01}+x_{12}+t_{12}}+e^{x_{02}+x_{12}+t_{22}}\right) \end{array}\)
- 这样就可以算出了crfloss
预测
维特比解码:
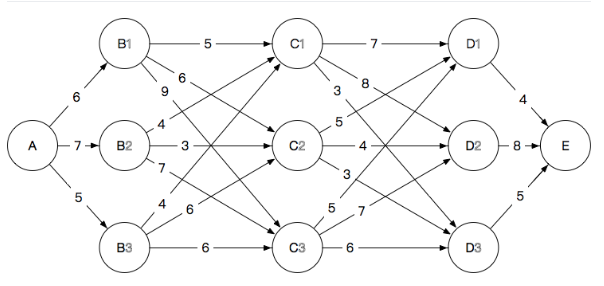
- A->B,路径长度为6,7,5
- A->B->C:确认到达C路过哪一个B
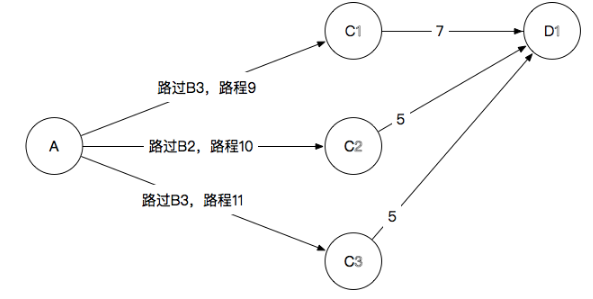
- C1:6+5=11,7+4=11,5+4=9,最终选择A->B3->C1,长度为9
- C2:12,10,11,最终选择A->B2->C2,长度10
- C3:15,14,11,最终选择A->B3->C3,长度为11
- 顺利到达C,同时得到了到每一个C的最短路程
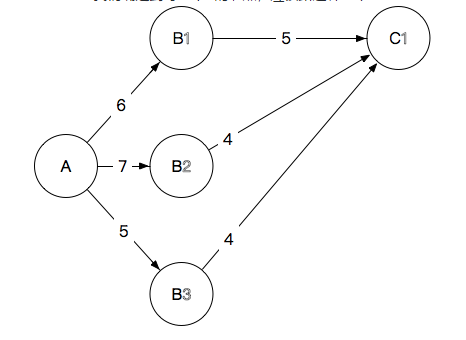
- A->B->C->D:确认到达D路过哪一个C
- D1:9+7=16,10+5=15,11+5=16,最终选择A→B2→C2→D1,抛弃其他到D1的路径,长度15
- D2:17,14,18,最终选择A→B2→C2→D2,抛弃其他到D2的路径,长度14
- D3:12,13,17,最终选择A→B3→C1→D3,抛弃其他到D3的路径,长度12
- 走到D,得到每一个D的最短路径
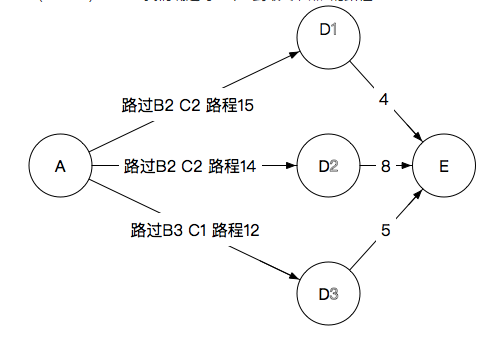
- A->B->C->D->E:确认到达E路过哪一个D
- 选择D3,完整路径为A→B3→C1→D3→E,路程为17
- 选择D3,完整路径为A→B3→C1→D3→E,路程为17
总结理解
bilstm后输出的是句子中词的特征,也就是说是crf的发射特征,传入crf基于crfloss计算转移特征。所以说,可以归结为一种深度网络+CRF的形式,前面的网络只是进行特征的抽取从而得到CRF的发射特征,后续的计算通过crfloss反向传播来得到转移特征。
在只有crf的情况下,特征是人为设定的,比如说某个字是名词或者说某个词是名词,上一个词是形容词等。