- 一、基本概念
- 二、学习器的选择
- 三、随机森林
- 四、AdaBoost
- 五、$GDBT$
- 六、$XGBOOST$
- 七、$LightGBM$
- 参考资料
- GDBT
- 一、基本概念
- 二、学习器的选择
- 三、随机森林
- 四、AdaBoost
- 五、$GDBT$
- 六、$XGBOOST$
- 七、$LightGBM$
- 参考资料
一、基本概念
- 集成学习是一种技术框架,其按照不同的思路来组合基础模型,从而达到其利断金的目的。
- 2种常见的集成学习框架:bagging,boosting(周志华机器学习)
- bagging:相互之间不存在强依赖关系,可以同时生成的并行化方法。
- boosting:存在强依赖,必须串行生成的方法。
二、学习器的选择
- 偏差描述预测与真实值的差异,方差描述预测值的离散程度
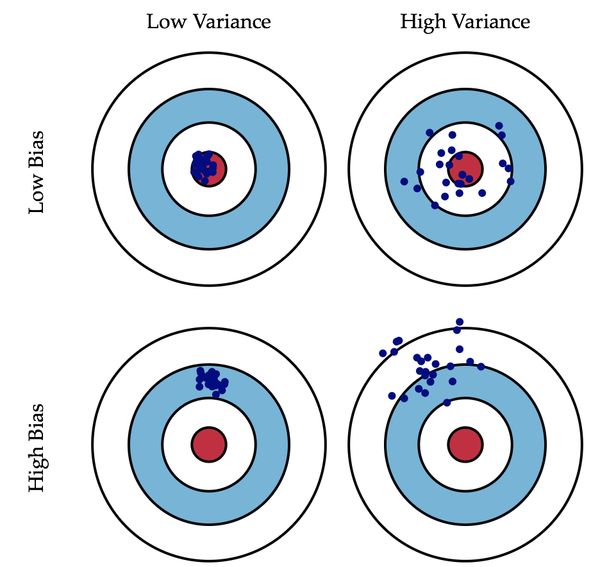
- 方差:就相当于模型在真实值的周边,但是比较分散
- 偏差:模型聚集在一起,不过偏离真实值
- 通常集成学习的基模型都是弱模型。boosting中的弱模型指的是高偏差低方差;bagging中的基模型是偏差低,方差高。
- 假设模型期望为\(\mu\),方差为\(\delta^2\),模型权重为\(r\),两两模型之间的相关系数为\(\rho\).
- 模型总体期望为:\(\begin{aligned} E(F) &=E\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} r_{i} E\left(f_{i}\right) \end{aligned}\)
- 模型的总体方差为:\(\begin{aligned} \operatorname{Var}(F) &=\operatorname{Var}\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} \operatorname{Var}\left(r_{i} f_{i}\right)+\sum_{i \neq j}^{m} \operatorname{Cov}\left(r_{i} f_{i}, r_{j} f_{j}\right) \\ &=\sum_{i}^{m} r_{i}^{2} \operatorname{Var}\left(f_{i}\right)+\sum_{i \neq j}^{m} \rho r_{i} r_{j} \sqrt{\operatorname{Var}\left(f_{i}\right)} \sqrt{\operatorname{Var}\left(f_{j}\right)} \\ &=m r^{2} \sigma^{2}+m(m-1) \rho r^{2} \sigma^{2} \\ &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \end{aligned}\)
- 对于\(bagging\):每个模型的权重等于\(\frac{1}{m}\)且期望近似相等,所以可以得到:\(\begin{aligned} E(F) &=\sum_{i}^{m} r_{i} E\left(f_{i}\right) \\ &=m \frac{1}{m} \mu \\ &=\mu \end{aligned}\)
- 对于bagging:方差:\(\begin{aligned} \operatorname{Var}(F) &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \\ &=m \frac{1}{m^{2}} \sigma^{2}(1-\rho)+m^{2} \frac{1}{m^{2}} \sigma^{2} \rho \\ &=\frac{\sigma^{2}(1-\rho)}{m}+\sigma^{2} \rho \end{aligned}\)
- 对于bagging:
- 期望:整体模型的期望等于基模型的期望,这就意味着整体模型的偏差和基模型的偏差近似
- 方差:整体模型的方差小于等于基模型的方差,当且晋档相关性为1时取等号,随着基模型数量的增加,整体模型的方差减小,从而防止过拟合的能力增强,模型的准确度提高。
- 对于boosting:基模型公用一套训练集合,所有基模型间有强相关性,近似等于1,则方差:\(\begin{aligned} \operatorname{Var}(F) &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \\ &=m \frac{1}{m^{2}} \sigma^{2}(1-1)+m^{2} \frac{1}{m^{2}} \sigma^{2} 1 \\ &=\sigma^{2} \end{aligned}\)
- 对于boosting:整体的方差与基模型的方差近似相等,整体模型的偏差由基模型累加而成。
- 总结:基模型的选择,需要各不相同,理想情况下,每个基模型都可以学习到不同的知识,从而整合起来完成整个任务。但是现实实现的时候很难找到各不相同的基模型,所以退而求其次的选择不是完全不同,但是又各有不同的基模型进行组合。在bagging中通过有放回的采样,针对每个基模型训练的数据不完全相同,在boosting中每次改变样本的分布,从而每个基模型训练的数据也不相同。
三、随机森林
- 概念:用随机的方式建立一个森林,森林里面有很多决策树,随机森林的每一个决策树之间是没有关联的。
- 对于使用:将一个新的输入送入模型,森林中的每一个决策树都对其进行判断,采取多数表决。
四、AdaBoost
通过改变训练数据的权值分布生成不同的分类器,使得被误分类的数据在最后的分类器中受到更到的重视。重点关注错分样本,准确率高的弱分类器权重大。
4.1、算法流程
- 输入:训练数据\(T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}\)其中\(x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}\),\(y_i \in y=\{-1,+1\}\)
- 输出:最终分类器\(G(x)\)
- 初始化训练数据的权值分布:\(D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N\)
- 对\(\quad m=1,2, \cdots, M\)
- 使用具有权值分布\(D_m\)的训练数据集学习,得到基本分类器\(G_m(x):\mathcal{X} -> \{-1,+1\}\)
- 计算\(G_m(x)\)在训练数据集上的误差率:\(e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)\)
- 计算\(G_m(x)\)的系数:\(\alpha_m = \frac{1}{2}ln \frac{1-e_m}{e_m}\)
- 更新训练数据权重分布: \(\begin{array}{c} D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N \end{array} \\ Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)\)
- 构建基本分类器的线性组合:\(f(x) = \sum_{m=1}^M \alpha_m G_m(x)\),最终分类器为:\(G(x) = sign(f(x)) = sign(\sum_{m=1}^M \alpha_m G_m(x))\)
- 整体是在对训练数据的分布进行改变。
4.2、\(Adaboost\)前向分布算法
- \(AdaBoost\)是加法模型,损失函数是指数函数,学习算法为前向分布算法的分类问题
- 加法模型表示我们最终学习到的强分类器是若干弱分类器加权平均得到\(f(x) = \sum_{m=1}^M \alpha_m G_m(x)\)
- 损失函数是指数函数:\(L(y, f(x)) = exp(-yf(x))\)
- 前向分步算法:
- 在第m轮迭代得到\(\alpha_m, G_m(x), f_m(x)\):\(f_m(x)=f_{m-1}(x)+\alpha_m G_m(x)\)
- 目标函数\(\arg \min _{\alpha, G} \sum_{i=1}^{N} \exp \left(-y_{i}\left(f_{m-1}\left(x_{i}\right)+\alpha G\left(x_{i}\right)\right)\right)\)
- 令\(\bar{w}_{m i}=\exp \left(-y_{i} f_{m-1}\left(x_{i}\right)\right)\)则目标函数为:\(\arg \min _{\alpha, G} \sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha G\left(x_{i}\right)\right)\)
- 求\(G_m^*\):
- 具有损失最小的第m个分类器为:\(G^{*}_{m}(x)=\arg \min _{G} \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G\left(x_{i}\right)\right)\)
-
代入损失函数得到\(L=\sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha_{m} G_{m}^{*}\left(x_{i}\right)\right)\) \(\begin{array}{l} \quad \sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha_{m} G^{*}_{m}\left(x_{i}\right)\right) \\ =\sum_{y_{i}=G_{m}\left(x_{i}\right)} w_{m i}^{-} e^{-\alpha}+\sum_{y_{i} \neq G_{m}\left(x_{i}\right)} w_{m i}^{-} e^{\alpha} \\ =e^{-\alpha} \sum_{y_{i}=G_{m}\left(x_{i}\right)} \bar{w}_{m i}+e^{\alpha} \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i} \\ =e^{-\alpha}\left(\sum_{i=1}^{N} \bar{w}_{m i}-\sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i}\right)+e^{\alpha} \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i} \\ =\left(e^{\alpha}-e^{-\alpha}\right) \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i}+e^{-\alpha} \sum_{i=1}^{N} \bar{w}_{m i} \\ =\left(e^{\alpha}-e^{-\alpha}\right) \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right)+e^{-\alpha} \sum_{i=1}^{N} \bar{w}_{m i} \end{array} \\ 令x = \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right), y = \sum_{i=1}^{N} \bar{w}_{m i}\)
-
对\(L = (e^{\alpha} + e^{-\alpha})x + e^{-\alpha}y\)对\(\alpha\)求导的:\(\alpha = \frac{1}{2}ln(\frac{y}{x}-1)\)
-
又因为:\(e_{m}=\frac{\sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right)}{\sum_{i=1}^{N} \bar{w}_{m i}}\)
- 所以:\(\alpha^{*}_{m}=\frac{1}{2} \ln \frac{1-e_{m}}{e_{m}}\)
- 前向分布算法不保证得到全局最优解
4.3、总结
- 可以在更新中加入学习率作为正则项。
- 对自定义损失函数不友好。
- 对异常点敏感。
五、$GDBT$
- 对于平方损失,h=1.\(g = -f_t(x) = y^{t-1} - y\),残差等于负梯度
- 对于其他损失函数,设h=1,舍弃高阶项,相当于拟合残差的近似值。 \(L(y, f(x)) = L(y, y^{t-1}+f_t(x))\\ 将其在L(y, y^{t-1})领域做二阶泰勒级数展开有\\ L(y, y^{t-1}+f_t(x)) = L(y, y^{t-1}) + gf_t(x) + \frac{1}{2}hf^2_t(x)\\ g = \frac{\partial L(y, y^{t-1})}{\partial y^{t-1}}\\ h = \frac{\partial L(y, y^{t-1})^2}{\partial y^{t-1}}\\ 求极值:g + hf_t(x)=0\\ f_t(x) = \frac{-g}{h}\)
- 上面是针对梯度和残差的说明

1
2
GDBT中的树通常是回归树,因为回归树的加减才有意义,分类树加减没有意义。
GDBT在做分类时也用的CART,针对每一个类别分别训练CART。比如现在有三个类别,那就针对每一个类别去训练相应的CART,同时这三个CART也是相互独立的。
六、$XGBOOST$
\(XGBoost\)是\(boosting\)算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为\(XGBoost\)是一种提升树模型。是在\(GDBT\)的基础上做了优化,更多的是针对工程上的优化,基本原理变化不大。
6.1、基本思想
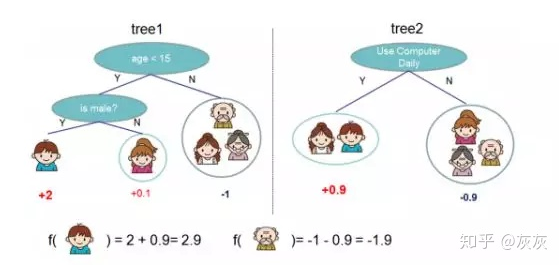
- 算法思想就是不断的添加树,不断的进行特征分裂来生成一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。
- 如图:训练出了两颗决策树,小孩的预测分数就是两棵树中小孩所落到的节点的分数相加,爷爷的预测分数同理:
6.2、基本原理
- \(XGBOOST\)的目标函数为: \(\begin{array}{c}{O b j=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}\right)+\sum_{k=1}^{K} \Omega\left(f_{k}\right)} \\ {\text { Training loss } \quad \text { Complexity of the Vrees }} \\ {\qquad \text { where } \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^{2}}\end{array}\)
- 目标函数由两部分构成,第一部分用来衡量预测分数和真实分数的差距,另一部分则是正则化项。正则化项同样包含两部分,T表示叶子结点的个数,w表示叶子节点的分数。γ可以控制叶子结点的个数,λ可以控制叶子节点的分数不会过大,防止过拟合。
- 新生成的树是要拟合上次预测的残差的,即当生成t棵树后,预测分数可以写成: \(\hat{y}_{i}^{(t)}=\hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\\ 同时,可以将目标函数改写成:\\ \mathcal{L}^{(t)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(\mathbf{x}_{i}\right)\right)+\Omega\left(f_{t}\right)\)
- 很明显,我们接下来就是要去找到一个\(f_t\)能够最小化目标函数。\(XGBoost\)的想法是利用其在\(f_t(x_i)\)处的泰勒二阶展开近似它。所以,目标函数近似为: \(\mathcal{L}^{(t)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(t-1)}\right)+g_{i} f_{t}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{t}\right)\\ 其中f_t(x_i)表示第t棵树,也就是\Delta x,y_i,\hat{y}^{t-1}表示前t-1棵树的预测值,相当于x\)
- 其中\(g_i\)为一阶导数,\(h_i\)为二阶导数: \(g_{i}=\partial_{\hat{y}^{(t-1)}} l\left(y_{i}, \hat{y}^{(t-1)}\right), \quad h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)\)
- 由于前t-1棵树的预测分数与y的残差对目标函数优化不影响,可以直接去掉。简化目标函数为: \(\tilde{\mathcal{L}}^{(t)}=\sum_{i=1}^{n}\left[g_{i} f_{t}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{t}\right)\)
- 上式是将每个样本的损失函数值加起来,我们知道,每个样本都最终会落到一个叶子结点中,所以我们可以将所以同一个叶子结点的样本重组起来,过程如下所示: \(\begin{aligned} O b j^{(t)} & \simeq \sum_{i=1}^{n}\left[g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\Omega\left(f_{t}\right) \\ &=\sum_{i=1}^{n}\left[g_{i} w_{q\left(x_{i}\right)}+\frac{1}{2} h_{i} w_{q\left(x_{i}\right)}^{2}\right]+\gamma T+\lambda \frac{1}{2} \sum_{j=1}^{T} w_{j}^{2} \\ &=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T \end{aligned}\)
- 定义 \(G_{j}=\sum_{i \in I_{j}} g_{i} \quad H_{j}=\sum_{i \in I_{j}} h_{i}\\ G_j :叶子结点 j 所包含样本的一阶偏导数累加之和,是一个常量\\ H_j :叶子结点 j 所包含样本的二阶偏导数累加之和,是一个常量\)
- 因此通过改写得到\(\sum_{j=1}^T [G_j w_j + \frac{1}{2}(H_j + \lambda)w_j^2] + \gamma T\),我们可以将目标函数改写成关于叶子结点分数w的一个一元二次函数,求解最优的w和目标函数值就变得很简单了,直接使用顶点公式即可。因此,最优的w和目标函数公式为: \(w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda} \quad O b j=-\frac{1}{2} \sum_{j=1}^{T} \frac{G_{j}^{2}}{H_{j}+\lambda}+\gamma T\)
- 通过一些列的代换化简,使得参数的计算变得简单
6.3、选择什么特征进行分裂
- 通过特征并行的方式并行计算选择要分裂的特征,尝试将各个特征作为分裂的特征,找到各个特征的最优分割点,计算根据其分割后产生的增益,选择增益最大的特征作为分裂的特征。
- 增益计算: \(\begin{aligned} \operatorname{Gain} &=\operatorname{Obj}_{L+R}-\left(O b j_{L}+O b j_{R}\right) \\ &=\left[-\frac{1}{2} \frac{\left(G_{L}+G_{R}\right)^{2}}{H_{L}+H_{R}+\lambda}+\gamma\right]-\left[-\frac{1}{2}\left(\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}\right)+2 \gamma\right] \\ &=\frac{1}{2}\left[\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}-\frac{\left(G_{L}+G_{R}\right)^{2}}{H_{L}+H_{R}+\lambda}\right]-\gamma \end{aligned}\)
- 停止分裂:gain设置阈值,树深度设置阈值等
6.4、选择什么分裂点位
- 全局扫描:将所有样本特征按照取值从小到大排列,将所有可能的分裂位置都尝试一遍,找到增益最大的分裂点,计算复杂度和叶子节点上的样本特征的取值个数成正比
- \(xgboost\)对最佳分裂点查找的优化:
- 特征预排序+缓存
- 分位点近似法:选择常数个特征值作为该特征的候选分割点
- 并行查找
6.5、 带权分位点近似法
6.5.1、\(\phi -quantile\)
\(Quantitle\)就是排序,假设现在有N个元素,那么\(\phi\) -quantile表示的就是指排序在\([\phi * N]\)的元素。比如\(S = [11,21,24,61,81,56,12,51]\),首选排序\(S=[11,12,21,24,39,51,56,61,81,89]\),则\(0.1-quantile=11,0.5-quantiles=39\)。但是这样误差会相对较大,所以就需要引入\(\epsilon -approximate \phi -quantiles\),从而对误差有所容忍。
6.5.2、 \(\epsilon -approximate \phi -quantiles\)
\(\epsilon -approximate \phi -quantiles\)就是在\([\lfloor(\phi-\epsilon) \times N\rfloor,\lfloor(\phi+\epsilon) \times N\rfloor]\)上进行排序,引用6.5.1的例子,取\(\epsilon=0.1\),则\(0.2-quantile={11,12,21}\)
6.5.3、$\epsilon -approximate -quantiles -summary$
还不理解。。。。。。。。。。。。。。。。。。。
6.6、$XGBOOST$的使用

七、$LightGBM$
在xgboost基础上做了优化: 数学原理上:
1
2
3
4
5
单边梯度抽样算法(Gradient-based One-Side Sampling, GOSS):梯度大则样本权重大,梯度小样本权重小,GOSS利用这一信息对样本抽样,保留梯度大的样本,对梯度小的样本进行采样。减小计算量。
直方图算法:基本思想将连续的特征离散化,在寻找最优分割点只需要遍历k个bin就行
互斥特征捆绑算法:对不怎么互斥的特征进行捆绑,可以降低特征数量
带深度限制的 Leaf-wise 算法
类别特征最优分割
工程上:
1
2
3
4
特征并行
数据并行
投票并行
缓存优化
参考资料
- 知乎
- CART回归树例子
- xgboost知乎
- xgboost知乎
- boosting知乎
- 集成学习知乎
- gdbt
- GDBT
- boosting知乎
- 集成学习知乎
- 分位数
- block
- GBM调参
- XGBOOST调参
-
GDBT
一、基本概念
- 集成学习是一种技术框架,其按照不同的思路来组合基础模型,从而达到其利断金的目的。
- 2种常见的集成学习框架:bagging,boosting(周志华机器学习)
- bagging:相互之间不存在强依赖关系,可以同时生成的并行化方法。
- boosting:存在强依赖,必须串行生成的方法。
二、学习器的选择
- 偏差描述预测与真实值的差异,方差描述预测值的离散程度
- 方差:就相当于模型在真实值的周边,但是比较分散
- 偏差:模型聚集在一起,不过偏离真实值
- 通常集成学习的基模型都是弱模型。boosting中的弱模型指的是高偏差低方差;bagging中的基模型是偏差低,方差高。
- 假设模型期望为\(\mu\),方差为\(\delta^2\),模型权重为\(r\),两两模型之间的相关系数为\(\rho\).
- 模型总体期望为:\(\begin{aligned} E(F) &=E\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} r_{i} E\left(f_{i}\right) \end{aligned}\)
- 模型的总体方差为:\(\begin{aligned} \operatorname{Var}(F) &=\operatorname{Var}\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} \operatorname{Var}\left(r_{i} f_{i}\right)+\sum_{i \neq j}^{m} \operatorname{Cov}\left(r_{i} f_{i}, r_{j} f_{j}\right) \\ &=\sum_{i}^{m} r_{i}^{2} \operatorname{Var}\left(f_{i}\right)+\sum_{i \neq j}^{m} \rho r_{i} r_{j} \sqrt{\operatorname{Var}\left(f_{i}\right)} \sqrt{\operatorname{Var}\left(f_{j}\right)} \\ &=m r^{2} \sigma^{2}+m(m-1) \rho r^{2} \sigma^{2} \\ &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \end{aligned}\)
- 对于\(bagging\):每个模型的权重等于\(\frac{1}{m}\)且期望近似相等,所以可以得到:\(\begin{aligned} E(F) &=\sum_{i}^{m} r_{i} E\left(f_{i}\right) \\ &=m \frac{1}{m} \mu \\ &=\mu \end{aligned}\)
- 对于bagging:方差:\(\begin{aligned} \operatorname{Var}(F) &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \\ &=m \frac{1}{m^{2}} \sigma^{2}(1-\rho)+m^{2} \frac{1}{m^{2}} \sigma^{2} \rho \\ &=\frac{\sigma^{2}(1-\rho)}{m}+\sigma^{2} \rho \end{aligned}\)
- 对于bagging:
- 期望:整体模型的期望等于基模型的期望,这就意味着整体模型的偏差和基模型的偏差近似
- 方差:整体模型的方差小于等于基模型的方差,当且晋档相关性为1时取等号,随着基模型数量的增加,整体模型的方差减小,从而防止过拟合的能力增强,模型的准确度提高。
- 对于boosting:基模型公用一套训练集合,所有基模型间有强相关性,近似等于1,则方差:\(\begin{aligned} \operatorname{Var}(F) &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \\ &=m \frac{1}{m^{2}} \sigma^{2}(1-1)+m^{2} \frac{1}{m^{2}} \sigma^{2} 1 \\ &=\sigma^{2} \end{aligned}\)
- 对于boosting:整体的方差与基模型的方差近似相等,整体模型的偏差由基模型累加而成。
- 总结:基模型的选择,需要各不相同,理想情况下,每个基模型都可以学习到不同的知识,从而整合起来完成整个任务。但是现实实现的时候很难找到各不相同的基模型,所以退而求其次的选择不是完全不同,但是又各有不同的基模型进行组合。在bagging中通过有放回的采样,针对每个基模型训练的数据不完全相同,在boosting中每次改变样本的分布,从而每个基模型训练的数据也不相同。
三、随机森林
- 概念:用随机的方式建立一个森林,森林里面有很多决策树,随机森林的每一个决策树之间是没有关联的。
- 对于使用:将一个新的输入送入模型,森林中的每一个决策树都对其进行判断,采取多数表决。
四、AdaBoost
通过改变训练数据的权值分布生成不同的分类器,使得被误分类的数据在最后的分类器中受到更到的重视。重点关注错分样本,准确率高的弱分类器权重大。
4.1、算法流程
- 输入:训练数据\(T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}\)其中\(x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}\),\(y_i \in y=\{-1,+1\}\)
- 输出:最终分类器\(G(x)\)
- 初始化训练数据的权值分布:\(D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N\)
- 对\(\quad m=1,2, \cdots, M\)
- 使用具有权值分布\(D_m\)的训练数据集学习,得到基本分类器\(G_m(x):\mathcal{X} -> \{-1,+1\}\)
- 计算\(G_m(x)\)在训练数据集上的误差率:\(e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)\)
- 计算\(G_m(x)\)的系数:\(\alpha_m = \frac{1}{2}ln \frac{1-e_m}{e_m}\)
- 更新训练数据权重分布: \(\begin{array}{c} D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N \end{array} \\ Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)\)
- 构建基本分类器的线性组合:\(f(x) = \sum_{m=1}^M \alpha_m G_m(x)\),最终分类器为:\(G(x) = sign(f(x)) = sign(\sum_{m=1}^M \alpha_m G_m(x))\)
- 整体是在对训练数据的分布进行改变。
4.2、\(Adaboost\)前向分布算法
- \(AdaBoost\)是加法模型,损失函数是指数函数,学习算法为前向分布算法的分类问题
- 加法模型表示我们最终学习到的强分类器是若干弱分类器加权平均得到\(f(x) = \sum_{m=1}^M \alpha_m G_m(x)\)
- 损失函数是指数函数:\(L(y, f(x)) = exp(-yf(x))\)
- 前向分步算法:
- 在第m轮迭代得到\(\alpha_m, G_m(x), f_m(x)\):\(f_m(x)=f_{m-1}(x)+\alpha_m G_m(x)\)
- 目标函数\(\arg \min _{\alpha, G} \sum_{i=1}^{N} \exp \left(-y_{i}\left(f_{m-1}\left(x_{i}\right)+\alpha G\left(x_{i}\right)\right)\right)\)
- 令\(\bar{w}_{m i}=\exp \left(-y_{i} f_{m-1}\left(x_{i}\right)\right)\)则目标函数为:\(\arg \min _{\alpha, G} \sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha G\left(x_{i}\right)\right)\)
- 求\(G_m^*\):
- 具有损失最小的第m个分类器为:\(G^{*}_{m}(x)=\arg \min _{G} \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G\left(x_{i}\right)\right)\)
-
代入损失函数得到\(L=\sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha_{m} G_{m}^{*}\left(x_{i}\right)\right)\) \(\begin{array}{l} \quad \sum_{i=1}^{N} \bar{w}_{m i} \exp \left(-y_{i} \alpha_{m} G^{*}_{m}\left(x_{i}\right)\right) \\ =\sum_{y_{i}=G_{m}\left(x_{i}\right)} w_{m i}^{-} e^{-\alpha}+\sum_{y_{i} \neq G_{m}\left(x_{i}\right)} w_{m i}^{-} e^{\alpha} \\ =e^{-\alpha} \sum_{y_{i}=G_{m}\left(x_{i}\right)} \bar{w}_{m i}+e^{\alpha} \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i} \\ =e^{-\alpha}\left(\sum_{i=1}^{N} \bar{w}_{m i}-\sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i}\right)+e^{\alpha} \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i} \\ =\left(e^{\alpha}-e^{-\alpha}\right) \sum_{y_{i} \neq G_{m}\left(x_{i}\right)} \bar{w}_{m i}+e^{-\alpha} \sum_{i=1}^{N} \bar{w}_{m i} \\ =\left(e^{\alpha}-e^{-\alpha}\right) \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right)+e^{-\alpha} \sum_{i=1}^{N} \bar{w}_{m i} \end{array} \\ 令x = \sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right), y = \sum_{i=1}^{N} \bar{w}_{m i}\)
-
对\(L = (e^{\alpha} + e^{-\alpha})x + e^{-\alpha}y\)对\(\alpha\)求导的:\(\alpha = \frac{1}{2}ln(\frac{y}{x}-1)\)
-
又因为:\(e_{m}=\frac{\sum_{i=1}^{N} \bar{w}_{m i} I\left(y_{i} \neq G_{m}\left(x_{i}\right)\right)}{\sum_{i=1}^{N} \bar{w}_{m i}}\)
- 所以:\(\alpha^{*}_{m}=\frac{1}{2} \ln \frac{1-e_{m}}{e_{m}}\)
- 前向分布算法不保证得到全局最优解
4.3、总结
- 可以在更新中加入学习率作为正则项。
- 对自定义损失函数不友好。
- 对异常点敏感。
五、$GDBT$
- 对于平方损失,h=1.\(g = -f_t(x) = y^{t-1} - y\),残差等于负梯度
- 对于其他损失函数,设h=1,舍弃高阶项,相当于拟合残差的近似值。 \(L(y, f(x)) = L(y, y^{t-1}+f_t(x))\\ 将其在L(y, y^{t-1})领域做二阶泰勒级数展开有\\ L(y, y^{t-1}+f_t(x)) = L(y, y^{t-1}) + gf_t(x) + \frac{1}{2}hf^2_t(x)\\ g = \frac{\partial L(y, y^{t-1})}{\partial y^{t-1}}\\ h = \frac{\partial L(y, y^{t-1})^2}{\partial y^{t-1}}\\ 求极值:g + hf_t(x)=0\\ f_t(x) = \frac{-g}{h}\)
- 上面是针对梯度和残差的说明
1
2
GDBT中的树通常是回归树,因为回归树的加减才有意义,分类树加减没有意义。
GDBT在做分类时也用的CART,针对每一个类别分别训练CART。比如现在有三个类别,那就针对每一个类别去训练相应的CART,同时这三个CART也是相互独立的。
六、$XGBOOST$
\(XGBoost\)是\(boosting\)算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为\(XGBoost\)是一种提升树模型。是在\(GDBT\)的基础上做了优化,更多的是针对工程上的优化,基本原理变化不大。
6.1、基本思想
- 算法思想就是不断的添加树,不断的进行特征分裂来生成一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。
- 如图:训练出了两颗决策树,小孩的预测分数就是两棵树中小孩所落到的节点的分数相加,爷爷的预测分数同理:
6.2、基本原理
- \(XGBOOST\)的目标函数为: \(\begin{array}{c}{O b j=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}\right)+\sum_{k=1}^{K} \Omega\left(f_{k}\right)} \\ {\text { Training loss } \quad \text { Complexity of the Vrees }} \\ {\qquad \text { where } \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^{2}}\end{array}\)
- 目标函数由两部分构成,第一部分用来衡量预测分数和真实分数的差距,另一部分则是正则化项。正则化项同样包含两部分,T表示叶子结点的个数,w表示叶子节点的分数。γ可以控制叶子结点的个数,λ可以控制叶子节点的分数不会过大,防止过拟合。
- 新生成的树是要拟合上次预测的残差的,即当生成t棵树后,预测分数可以写成: \(\hat{y}_{i}^{(t)}=\hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\\ 同时,可以将目标函数改写成:\\ \mathcal{L}^{(t)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(\mathbf{x}_{i}\right)\right)+\Omega\left(f_{t}\right)\)
- 很明显,我们接下来就是要去找到一个\(f_t\)能够最小化目标函数。\(XGBoost\)的想法是利用其在\(f_t(x_i)\)处的泰勒二阶展开近似它。所以,目标函数近似为: \(\mathcal{L}^{(t)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(t-1)}\right)+g_{i} f_{t}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{t}\right)\\ 其中f_t(x_i)表示第t棵树,也就是\Delta x,y_i,\hat{y}^{t-1}表示前t-1棵树的预测值,相当于x\)
- 其中\(g_i\)为一阶导数,\(h_i\)为二阶导数: \(g_{i}=\partial_{\hat{y}^{(t-1)}} l\left(y_{i}, \hat{y}^{(t-1)}\right), \quad h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)\)
- 由于前t-1棵树的预测分数与y的残差对目标函数优化不影响,可以直接去掉。简化目标函数为: \(\tilde{\mathcal{L}}^{(t)}=\sum_{i=1}^{n}\left[g_{i} f_{t}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{t}\right)\)
- 上式是将每个样本的损失函数值加起来,我们知道,每个样本都最终会落到一个叶子结点中,所以我们可以将所以同一个叶子结点的样本重组起来,过程如下所示: \(\begin{aligned} O b j^{(t)} & \simeq \sum_{i=1}^{n}\left[g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\Omega\left(f_{t}\right) \\ &=\sum_{i=1}^{n}\left[g_{i} w_{q\left(x_{i}\right)}+\frac{1}{2} h_{i} w_{q\left(x_{i}\right)}^{2}\right]+\gamma T+\lambda \frac{1}{2} \sum_{j=1}^{T} w_{j}^{2} \\ &=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T \end{aligned}\)
- 定义 \(G_{j}=\sum_{i \in I_{j}} g_{i} \quad H_{j}=\sum_{i \in I_{j}} h_{i}\\ G_j :叶子结点 j 所包含样本的一阶偏导数累加之和,是一个常量\\ H_j :叶子结点 j 所包含样本的二阶偏导数累加之和,是一个常量\)
- 因此通过改写得到\(\sum_{j=1}^T [G_j w_j + \frac{1}{2}(H_j + \lambda)w_j^2] + \gamma T\),我们可以将目标函数改写成关于叶子结点分数w的一个一元二次函数,求解最优的w和目标函数值就变得很简单了,直接使用顶点公式即可。因此,最优的w和目标函数公式为: \(w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda} \quad O b j=-\frac{1}{2} \sum_{j=1}^{T} \frac{G_{j}^{2}}{H_{j}+\lambda}+\gamma T\)
- 通过一些列的代换化简,使得参数的计算变得简单
6.3、选择什么特征进行分裂
- 通过特征并行的方式并行计算选择要分裂的特征,尝试将各个特征作为分裂的特征,找到各个特征的最优分割点,计算根据其分割后产生的增益,选择增益最大的特征作为分裂的特征。
- 增益计算: \(\begin{aligned} \operatorname{Gain} &=\operatorname{Obj}_{L+R}-\left(O b j_{L}+O b j_{R}\right) \\ &=\left[-\frac{1}{2} \frac{\left(G_{L}+G_{R}\right)^{2}}{H_{L}+H_{R}+\lambda}+\gamma\right]-\left[-\frac{1}{2}\left(\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}\right)+2 \gamma\right] \\ &=\frac{1}{2}\left[\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}-\frac{\left(G_{L}+G_{R}\right)^{2}}{H_{L}+H_{R}+\lambda}\right]-\gamma \end{aligned}\)
- 停止分裂:gain设置阈值,树深度设置阈值等
6.4、选择什么分裂点位
- 全局扫描:将所有样本特征按照取值从小到大排列,将所有可能的分裂位置都尝试一遍,找到增益最大的分裂点,计算复杂度和叶子节点上的样本特征的取值个数成正比
- \(xgboost\)对最佳分裂点查找的优化:
- 特征预排序+缓存
- 分位点近似法:选择常数个特征值作为该特征的候选分割点
- 并行查找
6.5、 带权分位点近似法
6.5.1、\(\phi -quantile\)
\(Quantitle\)就是排序,假设现在有N个元素,那么\(\phi\) -quantile表示的就是指排序在\([\phi * N]\)的元素。比如\(S = [11,21,24,61,81,56,12,51]\),首选排序\(S=[11,12,21,24,39,51,56,61,81,89]\),则\(0.1-quantile=11,0.5-quantiles=39\)。但是这样误差会相对较大,所以就需要引入\(\epsilon -approximate \phi -quantiles\),从而对误差有所容忍。
6.5.2、 \(\epsilon -approximate \phi -quantiles\)
\(\epsilon -approximate \phi -quantiles\)就是在\([\lfloor(\phi-\epsilon) \times N\rfloor,\lfloor(\phi+\epsilon) \times N\rfloor]\)上进行排序,引用6.5.1的例子,取\(\epsilon=0.1\),则\(0.2-quantile={11,12,21}\)
6.5.3、$\epsilon -approximate -quantiles -summary$
还不理解。。。。。。。。。。。。。。。。。。。
6.6、$XGBOOST$的使用
七、$LightGBM$
在xgboost基础上做了优化: 数学原理上:
1
2
3
4
5
单边梯度抽样算法(Gradient-based One-Side Sampling, GOSS):梯度大则样本权重大,梯度小样本权重小,GOSS利用这一信息对样本抽样,保留梯度大的样本,对梯度小的样本进行采样。减小计算量。
直方图算法:基本思想将连续的特征离散化,在寻找最优分割点只需要遍历k个bin就行
互斥特征捆绑算法:对不怎么互斥的特征进行捆绑,可以降低特征数量
带深度限制的 Leaf-wise 算法
类别特征最优分割
工程上:
1
2
3
4
特征并行
数据并行
投票并行
缓存优化