基础
缩小模型的方法:
1
2
3
Distillation:蒸馏,将大模型(可以是集成模型)的精华注入到小模型,使其具备接近大模型的能力。
Quantizationb:量化,将高精度模型用低精度表示。
Pruning:剪枝,将模型中作用小的部分舍弃。
==注意:对于nlp来说,蒸馏时目前比较实用的方法==
概念解释:
1
2
3
4
5
6
7
8
teacher:原始模型
student:新模型
transfer set:用于迁移teacher知识,训练studebt的数据集合
soft target:teacher输出的预测结果(通常是softmax之后的概率)
hard target:样本原本的标签
temperature:蒸馏目标函数中的超参数
born-again network:蒸馏的一种,指的是student和teacher的结构和尺寸完全一样
teacher annealing:防止student的标签杯teacher限制,在蒸馏的时候逐渐减少soft targets的权重。
比较直接的方法
==好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据== 以复杂模型得到的结果作为软目标,来进行模型的蒸馏。 \(q_{i}=\frac{\exp \left(z_{i} / T\right)}{\sum_{j} \exp \left(z_{j} / T\right)}\)
1
2
3
比如模型训练的过程中,模型会对每一种分类输出概率,正确的类别概率可能很大,其他的类型概率很小,但是这个很小的概率也表示了类别之间的一些相关特征。通过将这个softmax的结果进行平滑,也就是使得结果的熵变大,那么相对于真实的输出,软目标可以携带更多的信息。上面公式的T就表示对softmax结果的平滑处理。
将真实的标签和软标签同时使用,将两个目标函数加权平均,效果更佳。
理解Distilling the Knowledge in a Neural Network:
1
以大模型的预测结果为最后的标签,基于小模型去以这个预测标签为label进行有监督的训练,从而期望可以学习到大模型中的有用信息。
注意:
1
这种方法理论上是可以迁移任何的模型,但是对于模型的中间结果利用的不完全,也就是说只是利用了模型的输出结果的知识,模型的其他的中间知识并没有利用到。所以就更倾向于在基础结构相似的模型之间进行蒸馏,这样就可以充分的利用中间结果信息,原始model的所有的知识都可以被利用起来。DistillBert,TinyBert,就是其中的典型。
一些公式以及相关解释: \(\begin{array}{c} L_{s o f t}=-\sum_{j}^{N} p_{j}^{T} \log \left(q_{j}^{T}\right)=-\sum_{j}^{N} \frac{\exp \left(v_{j} / T\right)}{\sum_{k}^{N} \exp \left(v_{k} / T\right)} \frac{z_{j} / T}{\sum_{k}^{N} \exp \left(z_{k} / T\right)} \\ \frac{\partial L_{s o f t}}{\partial z_{i}}=-\frac{1}{T} \frac{\exp \left(v_{i} / T\right)}{\sum_{k}^{N} \exp \left(v_{k} / T\right)} \frac{\sum_{k}^{N} \exp \left(z_{k} / T\right)-\frac{z_{j}}{T} \exp \left(z_{j} / T\right)}{\left(\sum_{k}^{N} \exp \left(z_{k} / T\right)\right)^{2}} \\ =-\frac{1}{T} \frac{\exp \left(v_{i} / T\right)}{\sum_{k}^{N} \exp \left(v_{k} / T\right)}\left(\frac{1}{\sum_{k}^{N} \exp \left(z_{k} / T\right)}-\frac{1}{T} \frac{z_{j} \exp \left(z_{j} / T\right)}{\left(\sum_{k}^{N} \exp \left(z_{k} / T\right)\right)^{2}}\right) \end{array}\\ \begin{array}{l} L_{h a r d}=-\sum_{j}^{N} c_{j} \log \left(q_{j}^{1}\right)=-\sum_{j}^{N} c_{j} \frac{z_{i}}{\sum_{k}^{N} \exp \left(z_{k}\right)} \\ \frac{\partial L_{h a r d}}{\partial z_{i}}=-c_{i} \frac{1}{\sum_{k}^{N} \exp \left(z_{k}\right)} \end{array}\\ 因为:\frac{1}{\sum_{k}^{N} \exp \left(z_{k}\right)} \approx \frac{T}{\sum_{k}^{N} \exp \left(z_{k} / T\right)}\) 所以在同时使用soft target和hard target的时候,需要在soft target之前加上系数\(T^2\),这样才能保证两个的贡献度保持一致。
DistillBert
模型结构:
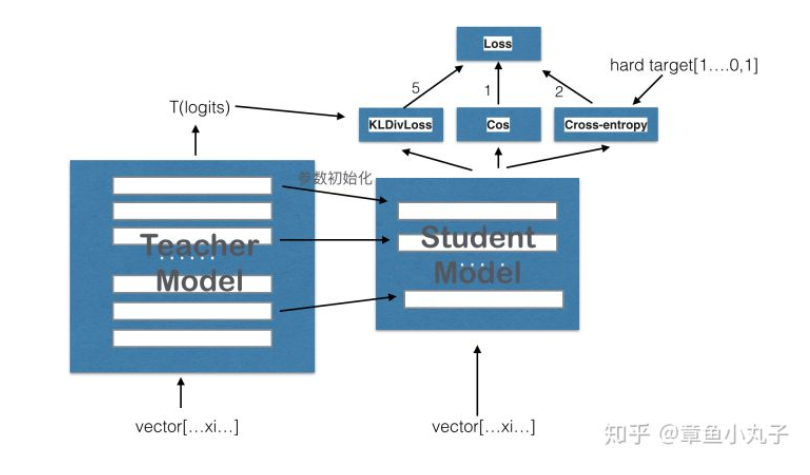
模型结构的描述:
1
2
3
每两层去掉一层(作者调研发现隐藏层的维度的变化比层数的变化对计算性能的影响较小)
去掉了token type embedding和pooler([CLS]的输出)
每一层加上初始化,用teacher模型初始化student模型
损失函数的定义: LCE损失:计算soft target和student的输出计算KL散度 \(\text {softmax-temperature: } p_{i}=\frac{\exp \left(z_{i} / 1\right)}{\sum_{j} \exp \left(z_{j} / T\right)}\) Lcos损失:计算teacher hidden state和student hidden state的余弦相似度(s的第一层对t的第二层,s的第二层对t的第四层) Lmlm损失:原始的bert的masked language model的损失函数。 整体计算公式为:\(Loss= 5.0*Lce+2.0* Lmlm+1.0* Lcos\)
结果:
1
模型的大小减小了40%,推理速度提升了60%,精确度下降了3%
Tinybert
图解TinyBert的学习:
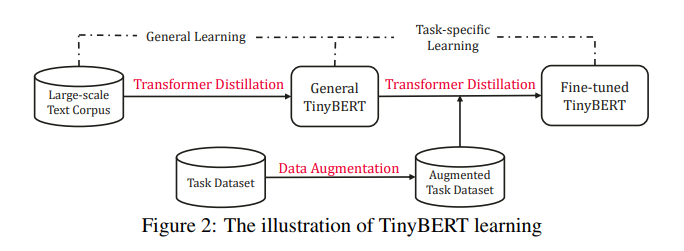
解释:
1
2
3
模型分为两个阶段的蒸馏:
对原始的bert进行蒸馏,相当于将base模型变小,保留一定的知识
然后再针对具体任务微调的时候再次进行蒸馏
网络结构:
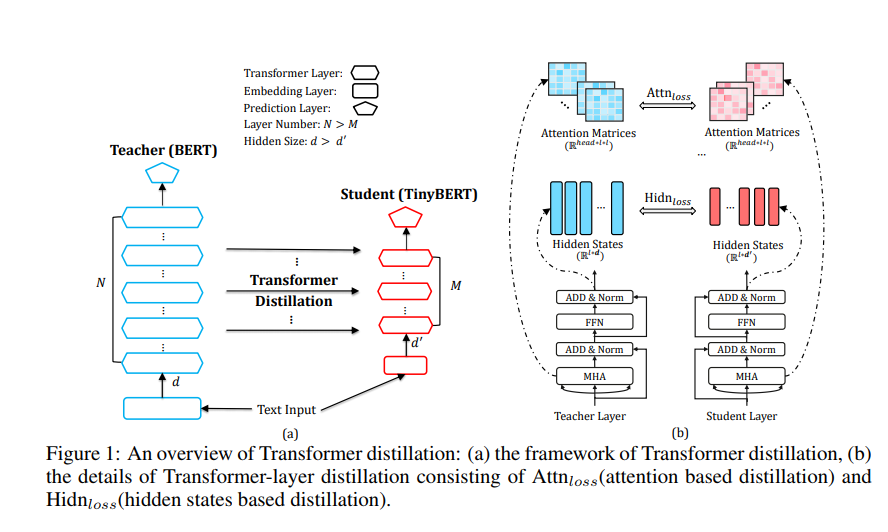
模型结构的描述:
1
2
模型结构左边表示对原始的bert进行蒸馏
右边表示针对任务的蒸馏
损失函数的定义: \(\mathcal{L}_{\text {layer }}\left(S_{m}, T_{g(m)}\right)=\left\{\begin{array}{ll} \mathcal{L}_{\text {embd }}\left(S_{0}, T_{0}\right), & m=0 \\ \mathcal{L}_{\text {hidn }}\left(S_{m}, T_{g(m)}\right)+\mathcal{L}_{\text {attn }}\left(S_{m}, T_{g(m)}\right), & M \geq m>0 \\ \mathcal{L}_{\text {pred }}\left(S_{M+1}, T_{N+1}\right), & m=M+1 \end{array}\right.\)
1
2
3
4
5
一共有四个损失函数:
embedding层的损失函数
隐藏层的损失函数
attention矩阵的损失函数
预测层的损失函数
\(\mathcal{L}_{\mathrm{embd}}=\operatorname{MSE}\left(\boldsymbol{E}^{S} \boldsymbol{W}_{e}, \boldsymbol{E}^{T}\right)\\ \mathcal{L}_{\mathrm{hidn}}=\operatorname{MSE}\left(\boldsymbol{H}^{S} \boldsymbol{W}_{h}, \boldsymbol{H}^{T}\right)\\ \mathcal{L}_{\text {pred }}=-\operatorname{softmax}\left(z^{T}\right) \cdot \log _{-} \operatorname{softmax}\left(z^{S} / t\right)\\ \mathcal{L}_{\mathrm{attn}}=\frac{1}{h} \sum_{i=1}^{h} \operatorname{MSE}\left(\boldsymbol{A}_{i}^{S}, \boldsymbol{A}_{i}^{T}\right)\)
结果:
1
模型缩小7.5倍,精确度下降不到3个点
训练方式:
1
2
3
4
1.对通用的bert进行蒸馏,不联合调整参数,得到一个通用的tinybert
2.用相关任务的数据对Bert进行fine-tune得到fine-tune的Berte模型
3.用2得到的模型再继续蒸馏得到fine-tune的student model base,注意这一步的student model base要用1中通用的student model base去初始化;(词向量loss + 隐层loss + attention loss)
4.重复第3步,但student model base模型初始化用的是3得到的student模型。(任务的预测label loss)