前深度学习
虽然深度学习现在遍地开花,但是传统的LR、FM等方法由于其可解释性墙,模型轻量,便于在线学习,仍然拥有很多的适用场景。同时每个模型也各有自己适用的场景, 没有一个通用模型来统一各个CTR场景。
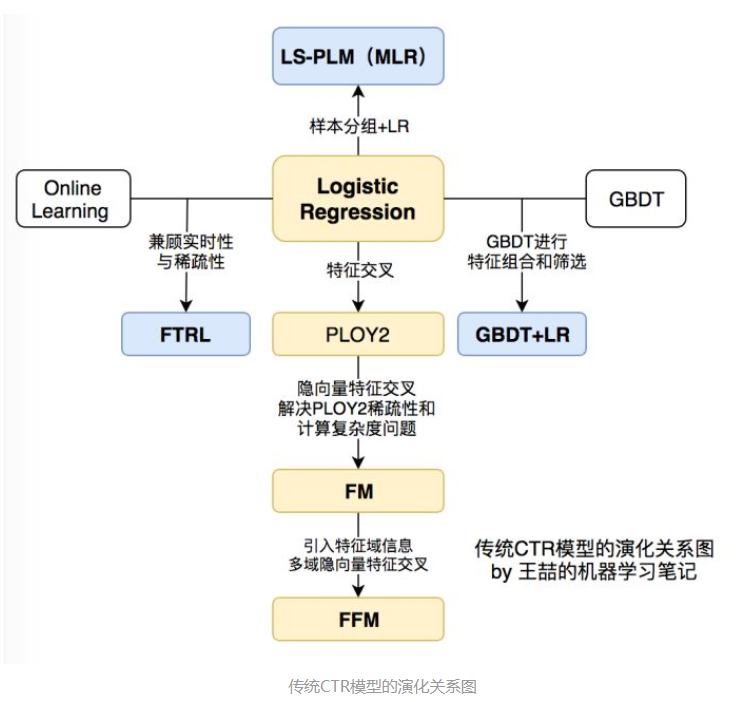
如上图所示为传统的CTR模型基本的演进过程。通过上图可以发现,整个演进以LR为基础向四周延展。
1
2
3
4
向下为了解决特征交叉的问题,演化为PLOY2、FM、FFM模型
向右为了使用模型,自动化的手段解决之前特征工程的难题,演化出GBDT+LR
向左为了解决时效性问题,提出FTRL
向上基于样本分组的思路增强模型的非线性,LS-PLM(MLR)模型
Logistic Regression(LR)
逻辑回归是对所有特征的一个线性加权组合,然后再加上sigmod逻辑函数:$\hat y(x)=w_0+ \sum_{i=1}^n w_i x_i$
Degree-2 Polynomial Margin(POLY2)
POLY2提出是特征交叉的开始。由于LR的变现能力比较初级,仅仅使用单一的特征,没有办法很好的利用高纬信息,在辛普森悖论现象下,只是用单一 特征进行判断, 甚至会出现错误的分析。
POLY2在LR的基础上进行了暴力的特征组合,就是所有特征两两相交,因此原始的LR就变成:$\hat{y}(x)=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n-1} \sum_{j=i+1}^{n} w_{i j} x_{i} x_{j}$
由公式了解到,POLY2是将所有的模型两两相交,暴力的组合了特征。结果是增加了特征维度,考虑了特征之间的关系,但是同时也增加了计算量,复杂度从n到$n^2$。维度很高,数据很稀疏的情况下,模型很难收敛。
Factorization Machine(FM)
FM的优势在于为每个特征学习一个隐权重向量,在进行特征交叉计算的时候,基于隐权重向量来计算。FM在POLY2的基础上融入了矩阵分解思想,在对二阶交叉特征的系数以矩阵分解的方式调整,让系数不再是独立无关的,同时也就解决了数据稀疏导致的无法训练参数的问题。$\hat y \mathbf (x):=w_0+\sum_{i=1}^n w_i x_i+\sum_{i=1}^n \sum_{j=i+1}^n\left\langle \mathbf v_i, \mathbf v_j \right\rangle x_i x_j$
其中,$w_0 \in R$,$w \in R^n$ ,$V \in R^{n.k}$, V是一个$n*k$的向量矩阵,n是特征x的个数,k是待定参数。 $<v_i, v_j>$表示点乘,也就是向量对应位置乘积的和。$<v_i, v_j> := \sum_{f=1}^k v_{i,f}.v_{j,f}$
由矩阵分解可知,对任意的正定矩阵W,都可以找到一个矩阵V,在V的维度k足够大的时候使得$W= VV^t$成立。因此,通过矩阵分解用两个向量$v_i, v_j$的内积近似还原表示W。同时,在拆分后,参数更新时是对两个向量分别更新,则在更新时,对于向量$v_i$,我们不需要寻找一组$x_i,x_j$同\时不为0,只需要在$x_i != 0 $的情况下,找到任意一个样本$x_k !=0$就可以通过$x_ix_k$来更新$v_i$
举例:
1
2
3
4
在商品推荐的场景下,样本有两个特征,分别是类品和品牌。某个训练样本的特征组合是(足球,阿迪达斯)。在POLY2模型中
只有当“足球”和“阿迪达斯”同时出现在一个训练样本中时,模型才能够学到这个组合特征对应的权重。而在因子分解机FM中,
“足球”的的隐向量也可以根据(足球,耐克)进行更新。“阿迪达斯”的隐向量也可以根据(篮球,阿迪达斯)更新,由此一来,
就大幅度的降低了模型对稀疏性的要求。
复杂度的降低:
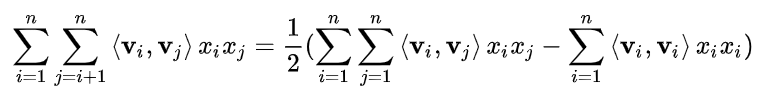 由于$<v_i, v_j> := \sum_{f=1}^k v_{i,f}.v_{j,f}$所以:
$$
由于$<v_i, v_j> := \sum_{f=1}^k v_{i,f}.v_{j,f}$所以:
$$
=\frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right)
=\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
=\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
$$
因此,化简后的公式为:
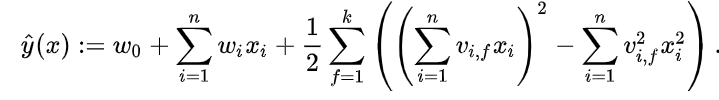 其计算复杂度为O(kn)
其计算复杂度为O(kn)
Field-aware Factorization Machine(FFM)
FFM是在FM的基础上增加了field的概念。

例子:
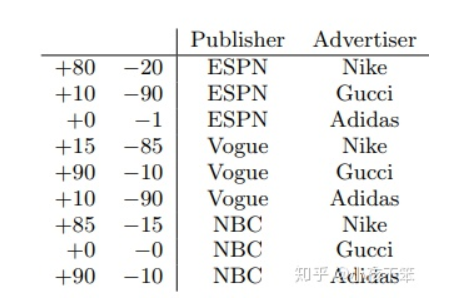
 可以看出使用 $V_{ESPN, A}$来学习(ESPN,Nike)的隐含含义,是因为Nike属于Advertiser这个field, 使用$V_{Nike, P}$,是因为ESPN属于Publisher这个field。同样地使用$V_{ESPN, G}$ 学习(ESPN,Male)的隐含含义,是因为Male属于为Gender的field,使用 $V_{Nike, P}$ 是因为ESPN属于为Publisher的field。
详细请点击
可以看出使用 $V_{ESPN, A}$来学习(ESPN,Nike)的隐含含义,是因为Nike属于Advertiser这个field, 使用$V_{Nike, P}$,是因为ESPN属于Publisher这个field。同样地使用$V_{ESPN, G}$ 学习(ESPN,Male)的隐含含义,是因为Male属于为Gender的field,使用 $V_{Nike, P}$ 是因为ESPN属于为Publisher的field。
详细请点击
GDBT+LR
这是特征工程模型化的开端,通过GDBT来发现特征的组合,增强LR的非线性学习能力。
 详情点击
详情点击
Follow-the-regularized-Leader(FTRL)
一种稀疏性好,精度可以接受的随机梯度下降算法。详情点击
Large Scale Piece-wise Linear Model(LS-PLM)
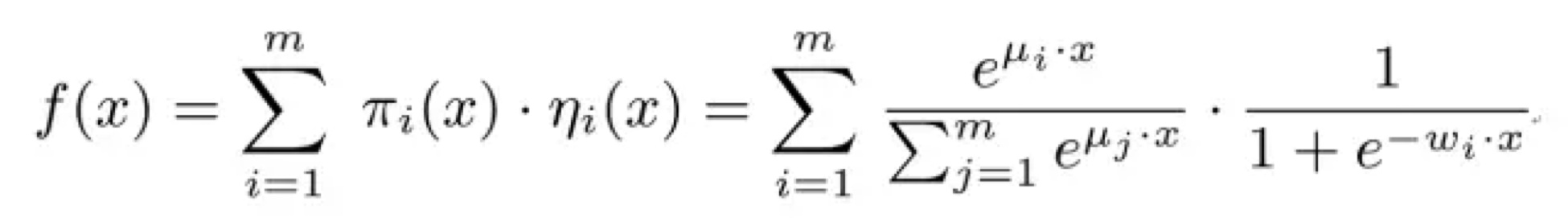 在LR的基础上分而治之,先对样本进行分片,再通过LR进行点击率预估。
举例说明:
在LR的基础上分而治之,先对样本进行分片,再通过LR进行点击率预估。
举例说明:
1
如果CTR模型要预估的是女性受众点击女装广告的CTR,显然我们并不希望把男性用户点击数码类产品的样本数据也考虑进来,因为这样的样本不仅对于女性购买女装这样的广告场景毫无相关性,甚至会在模型训练过程中扰乱相关特征的权重。为了让CTR模型对不同用户群体,不用用户场景更有针对性,其实理想的方法是先对全量样本进行聚类,再对每个分类施以LR模型进行CTR预估。
深度学习时代
深度学习时代,借鉴其再图像、语音、文本的发展成果,推进了ctr的效果。
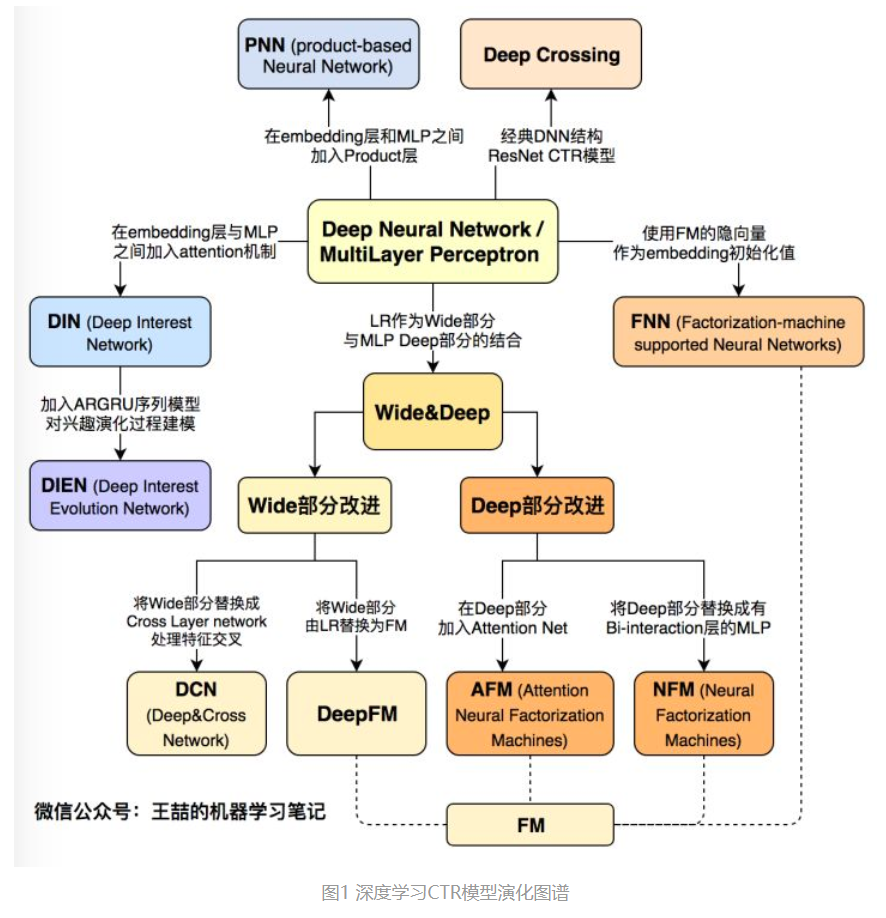 如图所示:深度学习时代,以dnn为核心,扩展出不同的深度模型。
如图所示:深度学习时代,以dnn为核心,扩展出不同的深度模型。
微软Deep Crossing(2016年)
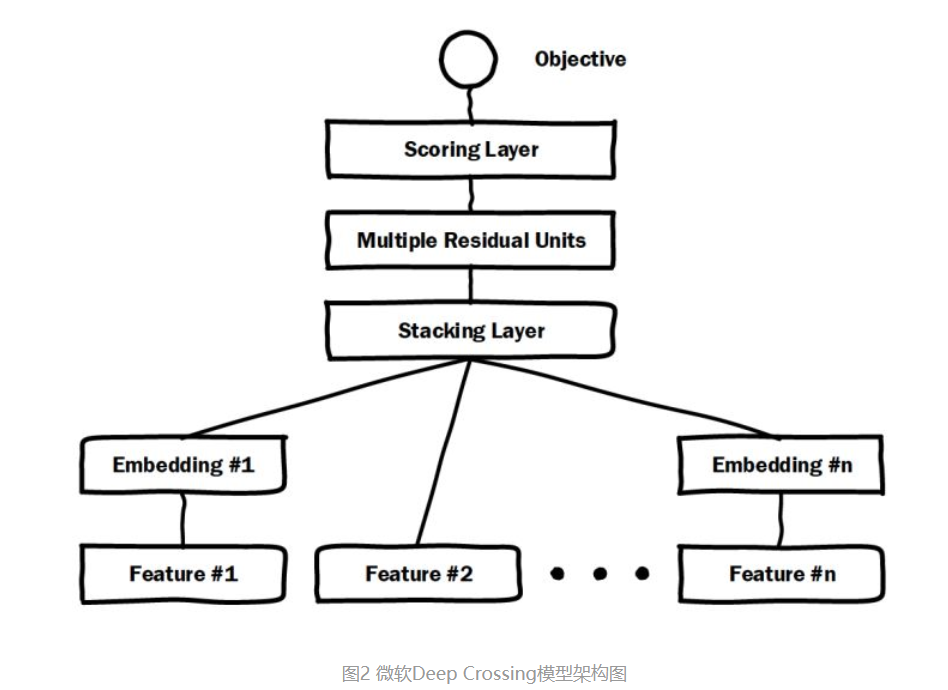 Deep Crossing可以说是深度学习CTR模型的最典型和基础性的模型,如上图所示。涵盖了CTR模型最典型的要素,既通过加入embedding层将稀疏特征转化为稠密特征,通过stacking layer将特征向量拼接,再通过多层神经网络完成特征的组合,最后通过scoring layer完成CTR的计算。与原始的DNN最不同的一点在于,DeepCrossing中加入了残差网络。
代码
Deep Crossing可以说是深度学习CTR模型的最典型和基础性的模型,如上图所示。涵盖了CTR模型最典型的要素,既通过加入embedding层将稀疏特征转化为稠密特征,通过stacking layer将特征向量拼接,再通过多层神经网络完成特征的组合,最后通过scoring layer完成CTR的计算。与原始的DNN最不同的一点在于,DeepCrossing中加入了残差网络。
代码
FNN(2016年)
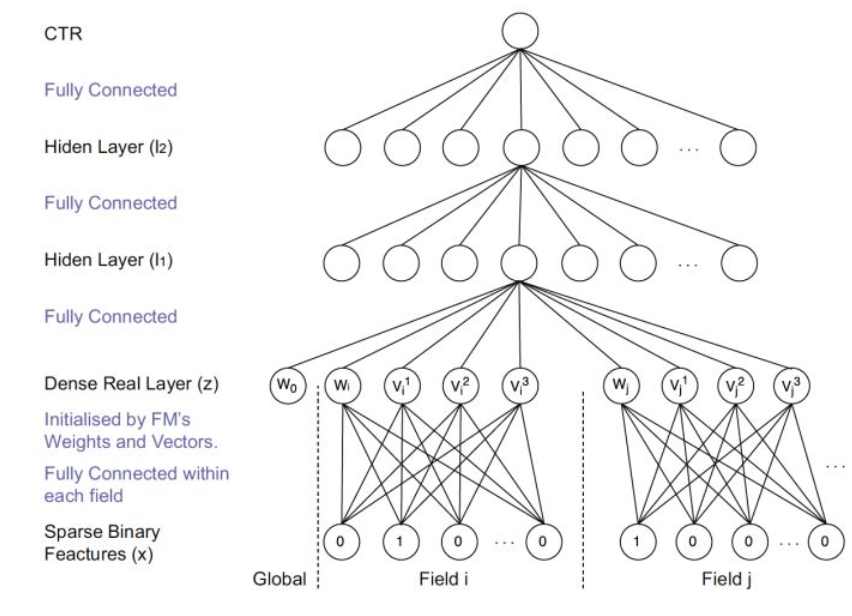 在Deep Crossing的基础上,使用FM的隐层向量作为user和item的embedding,从而避免了从完全随机状态训练Embedding。由于id类特征大量采用one-hot的编码方式,导致其维度极大,向量极稀疏,所以Embedding层与输入层的连接极多,梯度下降的效率很低,这大大增加了模型的训练时间和Embedding的不稳定性,使用pre train的方法完成Embedding层的训练,无疑是降低深度学习模型复杂度和训练不稳定性的有效工程经验。
代码
在Deep Crossing的基础上,使用FM的隐层向量作为user和item的embedding,从而避免了从完全随机状态训练Embedding。由于id类特征大量采用one-hot的编码方式,导致其维度极大,向量极稀疏,所以Embedding层与输入层的连接极多,梯度下降的效率很低,这大大增加了模型的训练时间和Embedding的不稳定性,使用pre train的方法完成Embedding层的训练,无疑是降低深度学习模型复杂度和训练不稳定性的有效工程经验。
代码
PNN (2016年)
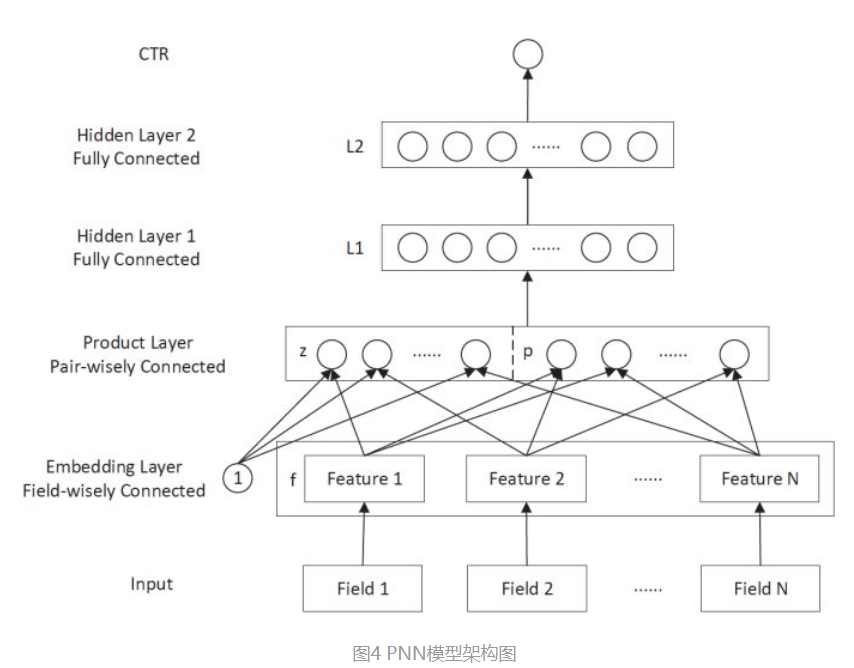 PNN的全称是Product-based Neural Network,主要是在DNN的基础上,在embedding和全连接层之间加上product layer用于实现不同种类特征之间的交互特征(学习filed之间的交互特征),然后全连接层再捕获高阶特征。
代码
PNN的全称是Product-based Neural Network,主要是在DNN的基础上,在embedding和全连接层之间加上product layer用于实现不同种类特征之间的交互特征(学习filed之间的交互特征),然后全连接层再捕获高阶特征。
代码
Google Wide&Deep(2016年)
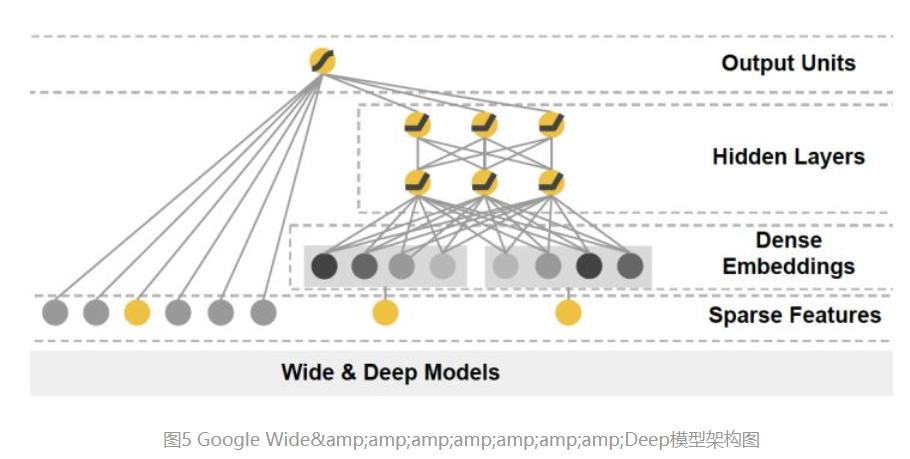 Wide&Deep:把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。
其中Wide部分:让模型具有记忆性,单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接记住用户的大量历史信息。
Deep部分:让模型具有泛化性,利用DNN表达能力强的特点,挖掘数据的深层含义。
将基于LR将Wide和Deep部分组合起来,形成统一模型。
wide&Deep:影响后续大量的模型采用两部分甚至多部分的组合形式,利用不同的结构挖掘不同的信息进行组合,充分利用和结合了不同网络结构的特点。
代码
Wide&Deep:把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。
其中Wide部分:让模型具有记忆性,单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接记住用户的大量历史信息。
Deep部分:让模型具有泛化性,利用DNN表达能力强的特点,挖掘数据的深层含义。
将基于LR将Wide和Deep部分组合起来,形成统一模型。
wide&Deep:影响后续大量的模型采用两部分甚至多部分的组合形式,利用不同的结构挖掘不同的信息进行组合,充分利用和结合了不同网络结构的特点。
代码
华为 DeepFM (2017年)——用FM代替Wide部分
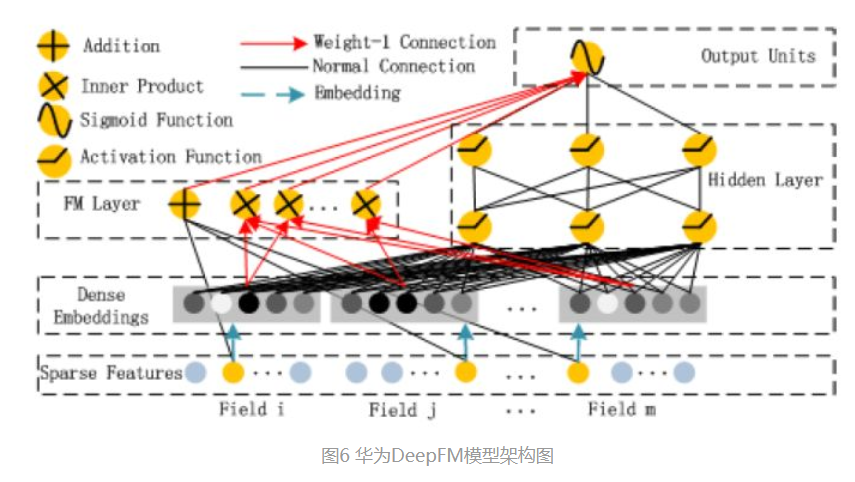 相较于Wide&Deep的改进在于,利用FM替换原始的WIde部分,加强了浅层网络部分特征的能力。
代码
相较于Wide&Deep的改进在于,利用FM替换原始的WIde部分,加强了浅层网络部分特征的能力。
代码
Google Deep&Cross(2017年)——使用Cross网络代替Wide部分
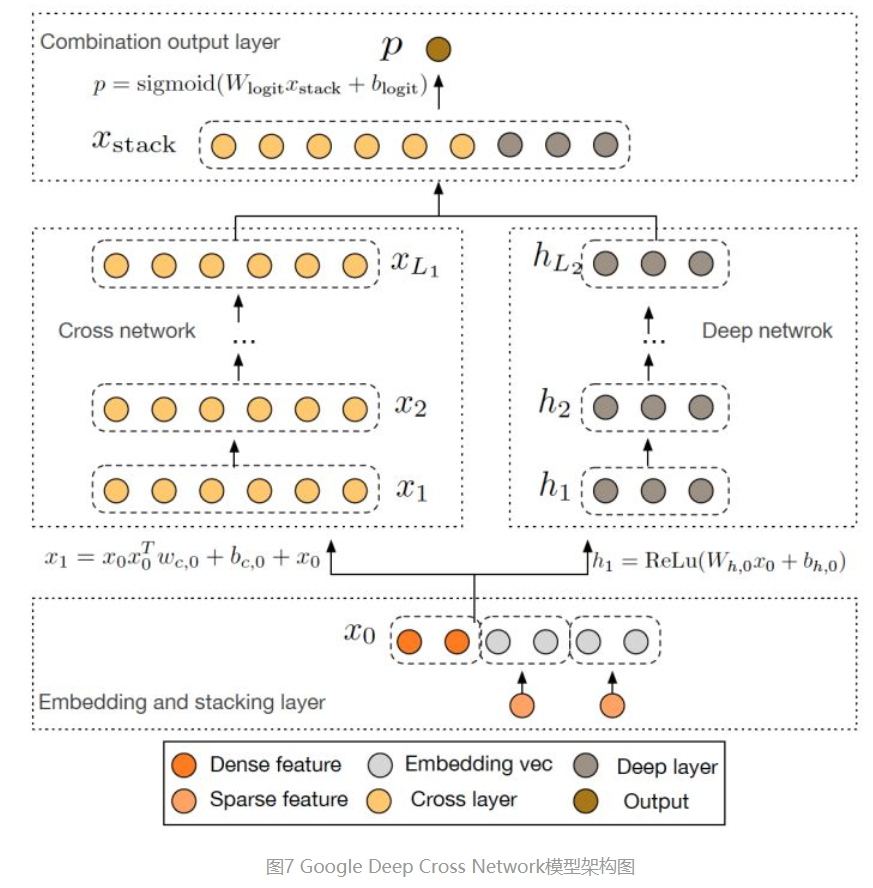 将Wide&Deep的wide部分用cross网络换掉。
Cross网络的作用主要是增强特征之间的交互力度。
代码
将Wide&Deep的wide部分用cross网络换掉。
Cross网络的作用主要是增强特征之间的交互力度。
代码
NFM(Neural Factorization Machines)(2017年)——对Deep部分的改进
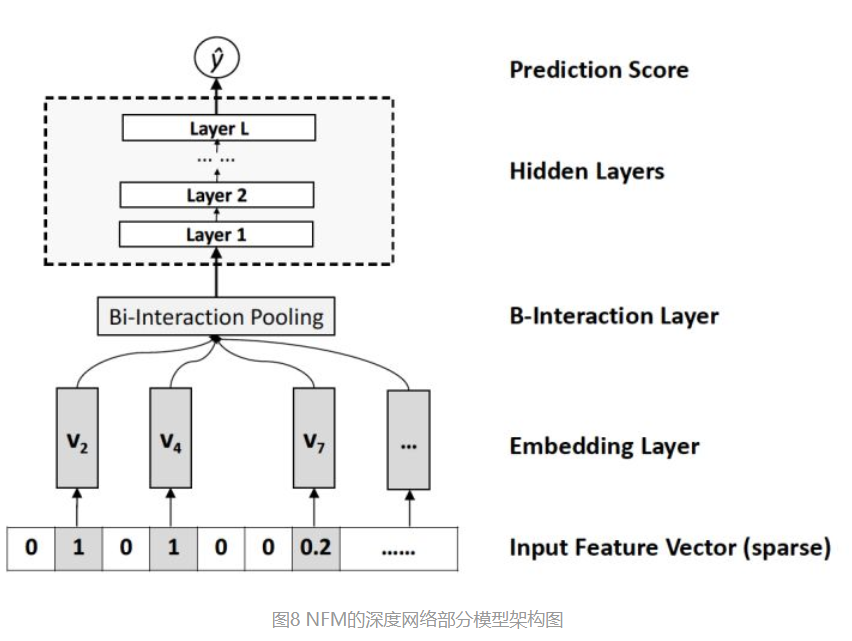 NFM是对Deep部分进行改进。从深度学习网络架构的角度看待FM,FM也可以看作是由单层LR与二阶特征交叉组成的Wide&Deep的架构,与经典W&D的不同之处仅在于Deep部分变成了二阶隐向量相乘的形式。再进一步,NFM从修改FM二阶部分的角度出发,用一个带Bi-interaction Pooling层的DNN替换了FM的特征交叉部分,形成了独特的Wide&Deep架构。其中Bi-interaction Pooling可以看作是不同特征embedding的element-wise product的形式。
NFM是对Deep部分进行改进。从深度学习网络架构的角度看待FM,FM也可以看作是由单层LR与二阶特征交叉组成的Wide&Deep的架构,与经典W&D的不同之处仅在于Deep部分变成了二阶隐向量相乘的形式。再进一步,NFM从修改FM二阶部分的角度出发,用一个带Bi-interaction Pooling层的DNN替换了FM的特征交叉部分,形成了独特的Wide&Deep架构。其中Bi-interaction Pooling可以看作是不同特征embedding的element-wise product的形式。
AFM(2017年)——引入Attention机制的FM
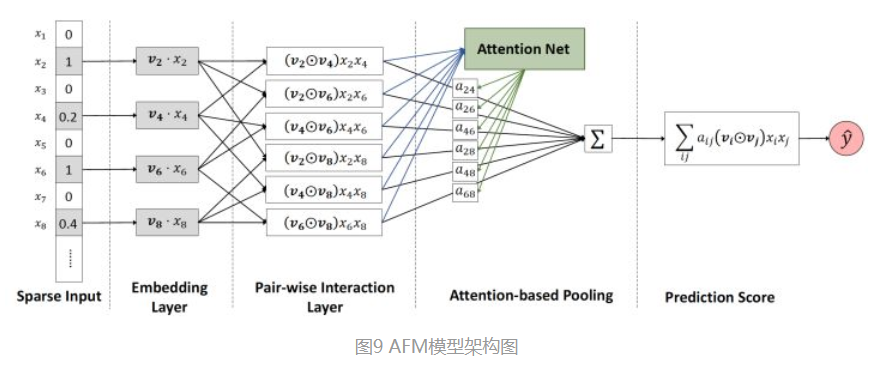 全称:Attentional Factorization Machines。模型结构上,AFM是对FM的二阶部分的每个交叉特征赋予了权重,这个权重控制了交叉特征对最后结果的影响,也就非常类似于NLP领域的注意力机制(Attention Mechanism)。为了训练Attention权重,AFM加入了Attention Net,利用Attention Net训练好Attention权重后,再反向作用于FM二阶交叉特征之上,使FM获得根据样本特点调整特征权重的能力。
全称:Attentional Factorization Machines。模型结构上,AFM是对FM的二阶部分的每个交叉特征赋予了权重,这个权重控制了交叉特征对最后结果的影响,也就非常类似于NLP领域的注意力机制(Attention Mechanism)。为了训练Attention权重,AFM加入了Attention Net,利用Attention Net训练好Attention权重后,再反向作用于FM二阶交叉特征之上,使FM获得根据样本特点调整特征权重的能力。
阿里DIN(2018年)——阿里加入Attention机制的深度学习网络
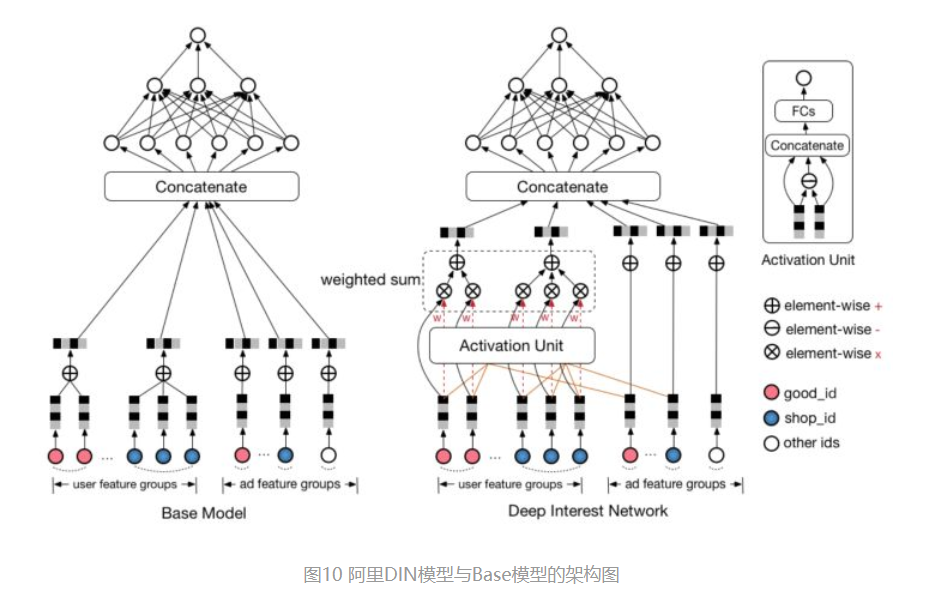 AFM在FM中加入了Attention机制,2018年,阿里巴巴正式提出了融合了Attention机制的深度学习模型——Deep Interest Network。与AFM将Attention与FM结合不同的是,DIN将Attention机制作用于深度神经网络,在模型的embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。
AFM在FM中加入了Attention机制,2018年,阿里巴巴正式提出了融合了Attention机制的深度学习模型——Deep Interest Network。与AFM将Attention与FM结合不同的是,DIN将Attention机制作用于深度神经网络,在模型的embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。
阿里DIEN(2018年)——DIN的“进化”
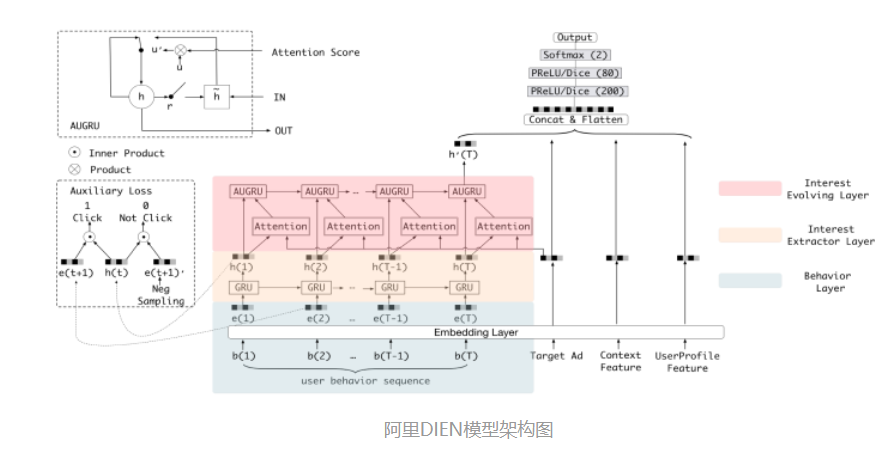 DIEN的全称为Deep Interest Evolution Network,它不仅是对DIN的进一步“进化”,更重要的是DIEN通过引入序列模型 AUGRU模拟了用户兴趣进化的过程。具体来讲模型的主要特点是在Embedding layer和Concatenate layer之间加入了生成兴趣的Interest Extractor Layer和模拟兴趣演化的Interest Evolving layer。其中Interest Extractor Layer使用了DIN的结构抽取了每一个时间片内用户的兴趣,Interest Evolving layer则利用序列模型AUGRU的结构将不同时间的用户兴趣串联起来,形成兴趣进化的链条。最终再把当前时刻的“兴趣向量”输入上层的多层全连接网络,与其他特征一起进行最终的CTR预估。
DIEN的全称为Deep Interest Evolution Network,它不仅是对DIN的进一步“进化”,更重要的是DIEN通过引入序列模型 AUGRU模拟了用户兴趣进化的过程。具体来讲模型的主要特点是在Embedding layer和Concatenate layer之间加入了生成兴趣的Interest Extractor Layer和模拟兴趣演化的Interest Evolving layer。其中Interest Extractor Layer使用了DIN的结构抽取了每一个时间片内用户的兴趣,Interest Evolving layer则利用序列模型AUGRU的结构将不同时间的用户兴趣串联起来,形成兴趣进化的链条。最终再把当前时刻的“兴趣向量”输入上层的多层全连接网络,与其他特征一起进行最终的CTR预估。