特征抽取
特征提取就是将一段音频信号中具有辨识性的信息提取出来一共后续系统使用。
而语音的特点,人产生的声音会被舌头、牙齿等声道形状过滤,如果准确的知道这些形状,就可以准确表示所产生的音素。声道的形状是在短时功率谱的包络中表现出来的,通过特征提取,得到这部分包络信息,就可以很好的表示语音信号。
MFCC
mfcc(Mel-scale Frequency Cepstral Coefficients)的提取流程为:语音-预加重-分帧-加窗-FFT-Mel滤波器组-对数运算-DCT。
预加重
对语音信号加一个高通滤波器:$H(Z) = 1 - \mu z^{-1}$ 其中$\mu$的值在0.9-1.0之间,通常取0.97。目的是使频谱变平坦,保持在低频和高频的整个频段中,同时也可以消除发生过程中声带和嘴唇的效应,也可以突出高频的共振峰。
分帧
语音信号是时变的辛亥,为了便于处理,假设在一个时间段内是稳定的。通常把语音信号分为20-49ms的帧。一般取25ms,如果才样品频率为16kHz,则一帧的采样点为16000*25/1000=400.一般在相邻的帧间每次移动19ms,这就意味着相邻的帧重叠的样本是240个。
加窗
通常是加汉明窗。汉明窗函数:$W(\eta , \alpha) = (1 - \alpha) - \alpha cos(2PIn/(N-1)) , \alpha = 0.46$.
通常一小段音频数据没有明显的周期性,加上汉明窗后,数据形状就有点周期的感觉了。
快速傅里叶变换
信号在时域上的变换不容易看出特性,通常转换到频域上的能量分布来观察,不同的能量分布,代表不同的语音信号特性。$X_a(K) = \sum_{n=0}^{N-1} x(n)e^{-jz\pi k/N}$。$x(n)$表示输入的语音信号。N表示傅里叶变换的点数。
三角带通滤波器
Mel Scale:频率到美尔频率的转换$M(f) = 1125ln(1+f/700)$ 美尔频率到频率:$M^{-1}(m) = 700(e^{m/1125-1})$
Mel频率滤波器组:
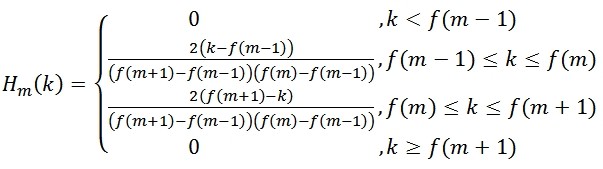 其中$\sum_{m=0}^{M-1} H_m(k) = 1$
其中$\sum_{m=0}^{M-1} H_m(k) = 1$
作用:对频谱进行平滑处理,消除谐波的作用,突出原有语音的共振峰。
对数计算
$s(m) = ln(\sum_{k=0}^{N-1} X_a(k)^2 H_m(k))$
DCT离散余弦变换
$C(n) = (\sum_{k=0}^{N-1} s(m) (\frac{\pi n(m-0.5)}{M})$
DCT的实质是去除各维信号之间的相关性,将信号映射到低维空间。
fbank
fbank就是再上面mfcc的基础上去掉最后一步得到
比较
FBank与MFCC对比: 1.计算量:MFCC是在FBank的基础上进行的,所以MFCC的计算量更大 2.特征区分度:FBank特征相关性较高(相邻滤波器组有重叠),MFCC具有更好的判别度,这也是在大多数语音识别论文中用的是MFCC,而不是FBank的原因 3.使用对角协方差矩阵的GMM由于忽略了不同特征维度的相关性,MFCC更适合用来做特征。 4.DNN,CNN可以更好的利用这些相关性,使用fbank特征可以更多地降低WER。
评价指标
常见的度量指标:
1
2
WER:词错误率
CER:字错误率
中文一般使用CER:$CER = \frac{S+D+I}{N}$ 其中S表示替换字符的数目 D表示删除的字符数目 I表示插入的字符数目 N表示参考序列中字符总数 由计算公式可知,CER的范围时[0, 无穷大) 其中分子的计算就是编辑距离
英文一般用WER,
1
https://github.com/PaddlePaddle/DeepSpeech/blob/develop/utils/error_rate.py