SpecAugment
构建一种直接作用于log mel频谱图的语音数据增强策略,从而帮助网络学习有用的特征。动机主要是:特征应该对在时间方向上的变形、频率信息的部分丢失、小段语音的丢失具有鲁棒性。
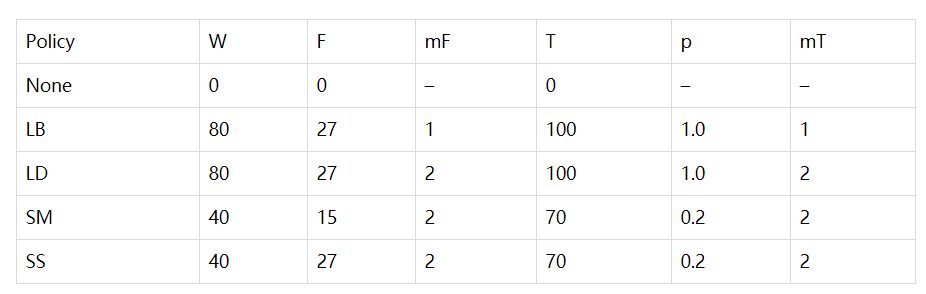
增强的策略有一下三种: 时间扭曲: 通过tensorflow的函数稀疏图像扭曲来应用与时间轴。给定具有$\tau$个时间步长的log mel频谱图,将其视为时间为水平轴,频率为垂直轴的图像。沿着水平线在时间步长为$(W, \tau - W)$内穿过图像中心的随机点应向左或者向右弯曲一段距离w,$0 <= w <= W$。 时间掩蔽:沿时间轴方向的$[t_0,t_0+t)$范围内的连续时间步进行掩蔽,其中$0=<t0<τ$,t服从$[0,T]$均匀分布。我们在时间掩码中引入了一个上限,以使时间掩码的宽度不能超过时间步数的p倍。 频率掩蔽:沿频域轴方向的$[f_0,f_0+f)$范围内的连续频率通道进行掩蔽,其中$0=<f0<ν$,f服从$[0,F]$均匀分布。ν是梅尔频道的数量
 从上到下依次为:原始信号,时间扭曲、频率屏蔽、时间屏蔽
从上到下依次为:原始信号,时间扭曲、频率屏蔽、时间屏蔽
相应的手动策略: