一些操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1.pandas获取行列数:列数df.shape[1] 行数df.sgape[0]
2.根据值定位元素:
值不大的情况: df.loc['20191228','B'] = 2222
值比较大的情况:
temp = (self.data['pid'] == np.int64(pid))
a = np.flatnonzero(temp)
temp = self.data.iloc[a[0]].tolist
3.pd转np: df.values、df.as_matrix()、np.array(df)
4.保存为csv:dt.to_csv('Result.csv',sep='?',na_rep='NA',float_format='%.2f',index=False)
5.将ndarray转为series
pred = pd.Series(y_pred.tolist())
6.DataFrame.info 显示DataFrame的简要摘要,显示有关DataFrame的有关信息,包括索引列的数据类型dtype和列的数据类型,非空值的数量和内存使用状况情况
7.DataFrame.fillna 填充缺失值
8.data.value_counts() 计算某列有那些不同的值,并计算每个值有多少重复值
9.添加表头:pd.read_csv('t.csv', header=None, names=['',''])
10.合并两个DataFrame:pd.concat([a,b])
11.获取DataFrame的前几列数据:df.head(5)
12.去重:df.drop_duplicates(subset=['query', 'label'], keep='first', inplace=True)
13.依据某个条件删除:df = df.drop(df[df.score < 50].index)
14.去掉df中已经采样过的数据样本:df2=df[~df.index.isin(df1.index)]
15.随机采样 df.sample(n=num, frac=0.8)
16.获取行列数:行,df.shape[0].列,df.shape[1]
17.shuffle:from sklearn.utils import shuffle df = shuffle(df)
18.删除行:data.drop(index = [3,4,5],inplace = True)
19.删除列:data.drop('fruit_label',axis = 1,inplace = True)#axis参数默认为0
20.series转DataFrame:dict_month = {'month':month.index,'numbers':month.values} df_month = pd.DataFrame(dict_month)
21.添加列名:df.columns = []
22.合并多列:df['date'] = df['year'].map(str)+"/"+df['month'].map(str)+"/"+df['day'].map(str)
23.where:myDF=peopleDF.where("age>21")
24.字典转dataframe:df = pd.DataFrame([dict])
25.groupby:df = df.groupby('A')['B'].apply(','.join).reset_index()
26.frame.sort_values(by='a')
27.改变列类型:df['col2'] = df['col2'].astype('int')
28.查看列类型:df.dtypes
29.求差集:_df = pd.concat([df1, df2, df2]).drop_duplicates(keep=False)
30.交集:intersected_df = pd.merge(df1, df2, how='inner')
31.df['Row_sum'] = df.apply(lambda x: x.sum(), axis=1) #按行求和,添加为新列
32.df.loc['Col_sum'] = df.apply(lambda x: x.sum()) # 各列求和,添加新的行
33.df.loc[df["sz"].isin([2,6]),"sz"]=-4 将sz列的值等于2或者6的替换为-4
34.df.withColumn("age",df.age.cast(IntegerType()))
df.withColumn("age",df.age.cast('int'))
错误纠正
1
2
错误提示:pandas.errors.ParserError: Error tokenizing data. C error: EOF inside string starting at line 15945
df = pd.read_csv(csvfile, quoting=csv.QUOTE_NONE, encoding='utf-8')
按照pid合并后面的数据:
1
2
3
4
5
6
7
8
9
10
11
def ab(df):
data = [eval(i) for i in df.values.tolist()]
res = []
for i in data:
res.extend(i)
data = list(set(res))
return " ".join('%s' %(id) for id in data)
df = pd.read_csv('eng.txt', sep='\t')
df = df.groupby(['pid'])['eng'].apply(ab)
df = df.reset_index()
字典读取为Dataframe
1
2
test_dict = {'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[90,89,99,78,97,93],'english':[89,94,80,94,94,90]}
test_dict_df = pd.DataFrame(test_dict)
字符串操作
1
2
3
4
5
6
7
8
9
10
11
12
13
#对字符串进⾏⼤写转换
s = strs.str.upper()
# 对字符串进⾏⼩写转换
ss = strs.str.lower()
match() 对每个元素调用 re.match(),返回布尔类型值
extract() 对每个元素调用 re.match(),返回匹配的字符串组(groups)
findall() 对每个元素调用 re.findall()
replace() 用正则模式替换字符串
contains() 对每个元素调用 re.search(),返回布尔类型值
count() 计算符合正则模式的字符串的数量
split() 等价于 str.split(),支持正则表达式
rsplit() 等价于 str.rsplit(),支持正则表达式
map or apply
1
2
3
4
5
6
7
data['index'].map(lambda x: fun(x))
map也可以替换为apply
传两个参数:
def sum_test(a,b):
return a+b
data4['数学'+'评级']=data4.apply(lambda x: sum_test(x['语文'],x['数学']),axis=1)
merge join concat
merge
merge相当于sql的join操作,实践将两个DataFrame根据一些共有的列连接起来。模式有默认inner,left、right、outer几种:
inner
1
2
3
4
5
6
7
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
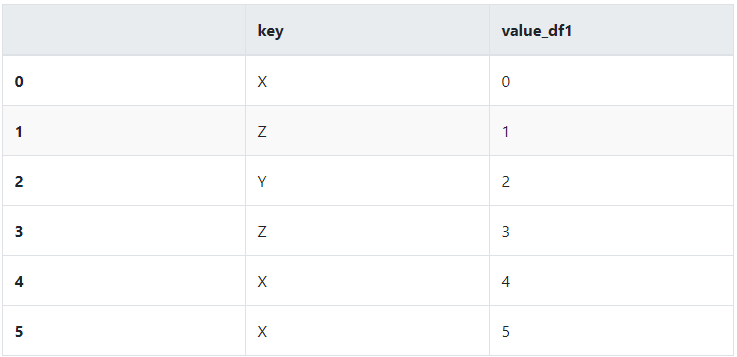
dframe1 = DataFrame({'key':['X','Z','Y','Z','X','X'],'value_df1': np.arange(6)})
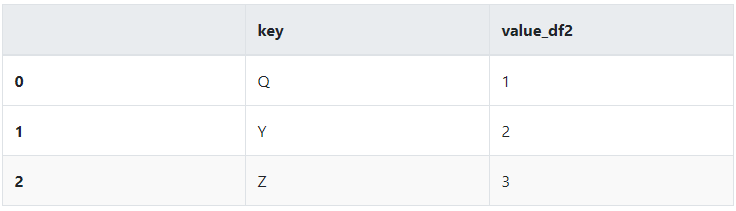
dframe2 = DataFrame({'key':['Q','Y','Z'],'value_df2':[1,2,3]})
# pd.merge(dframe1,dframe2)
pd.merge(dframe1,dframe2,on='key',how='inner')
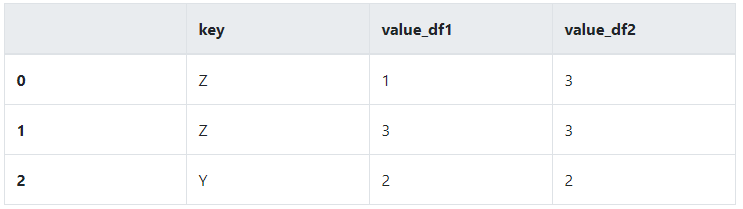
left
1
pd.merge(dframe1,dframe2,on='key',how='left')
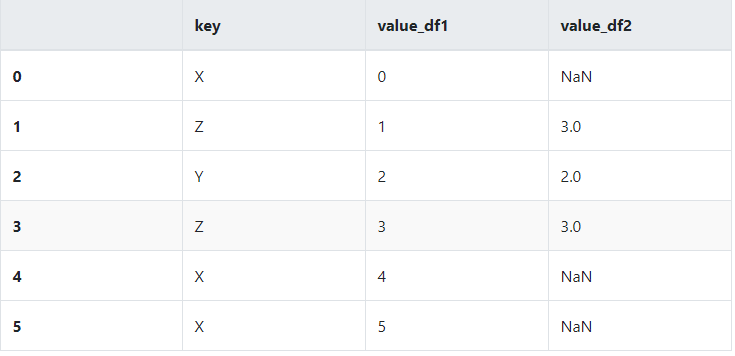
right
1
pd.merge(dframe1,dframe2,on='key',how='right')
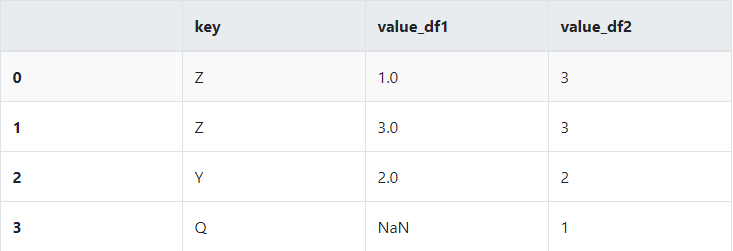
outer
1
pd.merge(dframe1,dframe2,on='key',how='outer')
注意以上都支持多个key上的merge
join
1
2
3
4
5
6
7
8
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']},
index = ['K0', 'K1', 'K2', 'K3'])
right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index = ['K0', 'K1', 'K2', 'K3'])
left.join(right)

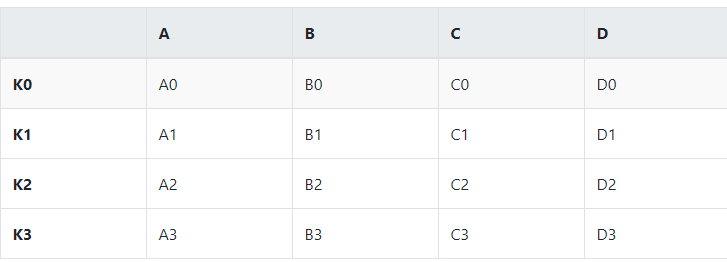
Concat
1
2
3
4
5
6
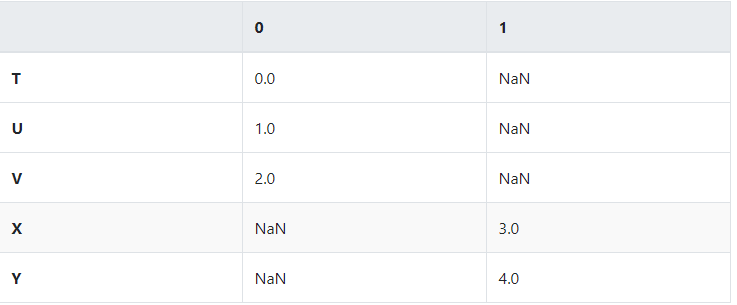
# Lets create two Series with no overlap
ser1 = Series([0,1,2],index=['T','U','V'])
ser2 = Series([3,4],index=['X','Y'])
#Now let use concat (default is axis=0)
pd.concat([ser1,ser2])
pd.concat([ser1,ser2],axis=1,sort =True) # sort=Ture是默认的,pandas总是默认index排序

pandas vs mysql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import pandas as pd
from sqlalchemy import create_engine
#创建engine
engine= create_engine('mysql+pymysql://用户名:密码@host:port/db_name?charset=utf8')
#数据查询
sql="select * from test_table ;"
data=pd.read_sql(sql_need,engine)
#数据导入
table_name='test_table'
data.to_sql(table_name,con=sql_engine,index=False,if_exists='append')
#创建、修改和删除
sql="delete from test_table where col_a='a'"
engine.execute(sql)
conn = pymysql.connect(host='',port=3306, user='', passwd='', db='',charset='utf8')
df = pd.read_sql(sql, con=conn)